

生成AIの急速な普及により、AIチップ市場はこれまでにない成長局面を迎えています。
2nm世代の量産競争、HBMの供給逼迫、先端パッケージ(CoWoS)の増産、そしてデータセンターの電力制約。
現在のAIチップ競争は、微細化やトランジスタ数の増加だけでは実現はできません。
AIモデルの巨大化に伴い、チップ内部・チップ間・パッケージ全体で必要とされる
配線量と接続密度が急激に増えています。
そのため、従来の「トランジスタを増やせば性能が伸びる」という前提は崩れています。
本コラムでは、2nm世代で注目されるBSPDN、HBMの課題、RDLやCoWoSの先端パッケージ技術を整理しながら、
AIチップ競争の根本が“配線密度”へと移行している構造を解説します。
2nm世代とBSPDNの本質 (微細化だけではAIチップは伸びない)
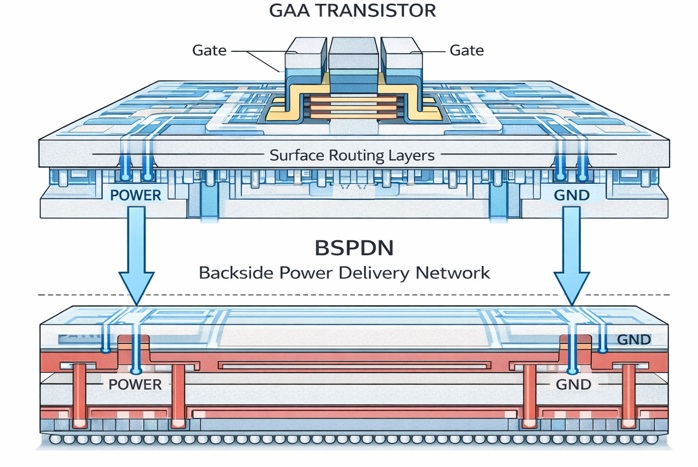
2nm世代では、GAA(Gate-All-Around)構造が本格的に導入され、トランジスタの制御性と電力効率が大きく改善しています。
TSMC や Samsung Electronics は、微細化による性能向上に加えて、BSPDN(Backside Power Delivery Network)を次の重要技術として開発・量産化を進めています。
BSPDNは、電源配線をチップ裏面に移すことで、
- IRドロップの低減
- 表面配線層の有効活用
- 配線混雑の緩和
といった効果をもたらし、これにより、トランジスタの性能をより引き出しやすくしています。
「FinFET → GAA → BSPDN の比較表」
| 項目 | FinFET | GAA | BSPDN |
| 電力効率 | △ | ○ | ◎ |
| 配線混雑 | △ | △ | ◎ |
| IRドロップ | △ | △ | ◎ |
| 微細化適性 | ○ | ◎ | ◎ |
しかし、AIチップの実際の性能を決めるのは、トランジスタそのものよりも配線の遅延と混雑です。
AIチップが大きくなると、内部の配線が細く長くなり、信号伝達の遅れが増えてしまいます。
その遅れが全体の処理速度に影響するため、トランジスタ数を増やしても性能がそのまま比例して向上するわけではありません。
2nm世代の競争は、「どれだけトランジスタを作れるか」ではなく、
「どれだけ高密度に、効率よく接続できるか」
へと移行しています。
BSPDNは、その課題を克服する重要な技術です。
AIチップとHBM (メモリ帯域が性能を支配する理由)
現在のAIチップ性能は、演算器の数よりもメモリ帯域によって大きく左右されます。
NVIDIA をはじめとする最新GPUが複数のHBMを搭載するのは、AIモデルの巨大化により、
パラメータを読み出す速度が性能の上限を決めるためです。
AIモデルは数百億〜数兆パラメータ規模へと拡大し、演算器がどれだけ高速でも、
メモリからデータを供給できなければ処理が停滞してしまいます。
そのため、
HBMはAIチップの“実効性能”を決める最重要コンポーネント
となっています。
HBMはTSV(Through-Silicon Via)を用いた3D積層構造を採用していますが、
以下のような課題を抱えています。
- スタック高さの増大による発熱集中
- TSV工程の歩留まり低下
- 積層数増加に伴う製造コストの上昇
- 供給能力の制約
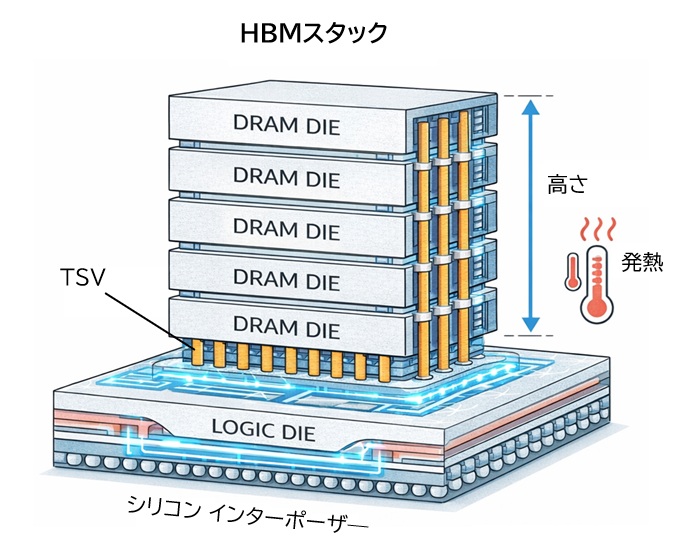
これらの要因により、HBMの帯域向上ペースはロジック側の微細化ほど速くありません。
ロジックが2nmへ進んでも、HBMの密度や帯域が追いつかなければ、
システム全体の性能は頭打ちになります。
つまり、AIチップの競争力は、
「ロジック密度 × メモリ接続密度」
の掛け算で決まり、どちらか一方だけを強化しても性能は伸びにくい構造になっています。
HBMは単なるメモリではなく、AIチップの性能を決定づける“帯域インフラ”であり、
その進化がAIモデルの進化速度を左右すると言えます。
RDLとCoWoS(先端パッケージが“前工程化”する)
AIチップでは、HBMとロジックを高帯域で接続するために、
RDL(Redistribution Layer)や先端パッケージ技術が急速に進化しています。
特にTSMCのCoWoSは、AIチップの構造そのものを規定する中核技術となっています。
従来のパッケージは「後工程」として扱われてきましたが、AIチップでは事情が大きく変わっています。
HBMとロジックを広帯域で接続するためには、
微細なRDL配線や大面積インターポーザが必要となり、その設計・製造は前工程と同等の難易度と重要性を持つようになっています。
しかし、大面積インターポーザや微細RDLには、次のような課題が存在します。
- 大面積化による反りの発生
- 熱膨張差による応力集中
- 微細RDLの歩留まり低下
- 製造コストの増大
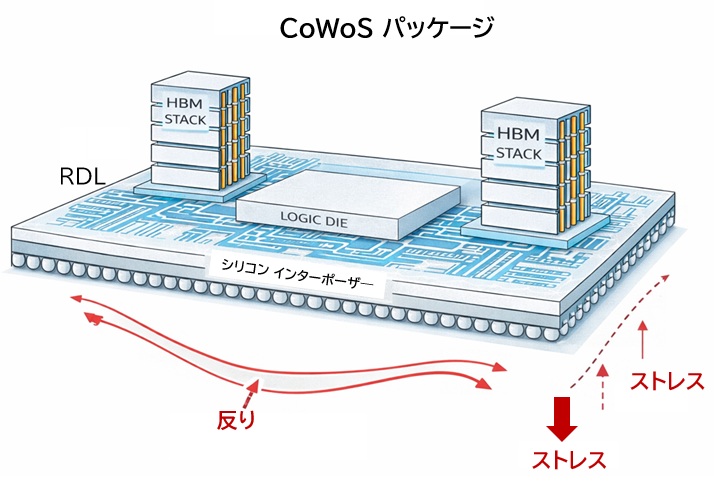
これらの課題は、
ロジック設計・前工程・後工程・熱設計が一体となった最適化
が求められています。
従来パッケージ vs 先端パッケージ(CoWoS)の比較
| 項目 | 従来パッケージ | CoWoS |
| 配線幅 | 太い | 微細 |
| 帯域 | 低い | 高い |
| 面積 | 小さい | 大面積 |
| 歩留まり | 高い | 課題あり |
| 熱 | 低い | 高い |
AIチップは、HBM、ロジック、インターポーザ、RDLが一体となった“パッケージ内システム”として設計されることで、初めて高い帯域と効率を実現できます。
そのため、先端パッケージは後工程ではなく、AIチップの性能を決める“前工程化した領域”として扱われるようになっているのです。
“配線密度競争”とは何か(2nm・HBM時代の新しい競争軸)
AIチップの競争は、これまでの「微細化によるトランジスタ増加」ということだけで説明はできません。
2nm世代、HBM、先端パッケージが同時に進化する現在、性能を決める要素は
“どれだけ高密度に接続できるか”
へ変わりました。
AIチップの構造を大きく分けると、次の3つの要素で構成されています。
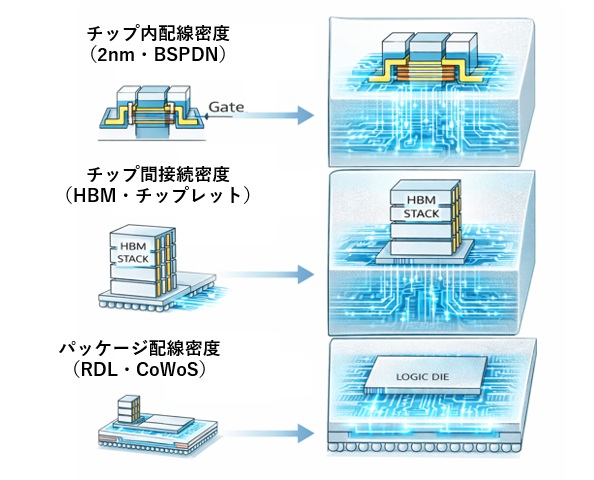
- チップ内配線密度(2nm・BSPDN)
トランジスタを増やしても、配線が混雑すれば性能は向上しません。
2nm世代ではBSPDNによって電源配線を裏面化し、表面配線層を信号配線に割り当てることで、配線密度を高めています。 - チップ間接続密度(HBM・チップレット)
AIモデルの巨大化により、HBMとの接続帯域が性能の上限を決めています。
ロジックが高速化しても、HBM側の帯域が追いつかなければ性能は頭打ちになります。 - パッケージ配線密度(RDL・CoWoS)
HBMとロジックをつなぐRDLやインターポーザは、もはや後工程ではなく、
チップ性能を左右する“前工程化した領域”となっています。
これらの要素のいずれかが十分な接続能力を確保できないと、AIチップ全体の性能は制約されます。
そのため、トランジスタ数は重要でありながらも、もはや“前提条件”に過ぎません。
AIチップの競争の核心は、ロジック・メモリ・パッケージをまたぐ接続構造をどれだけ最適化できるかにあります。
設計、前工程、後工程、電源供給、熱設計を一体で最適化できる企業だけが、
次世代AIチップで優位に立つことができる段階となっています。
2030年のAI半導体(チップレットと電力制約の未来)
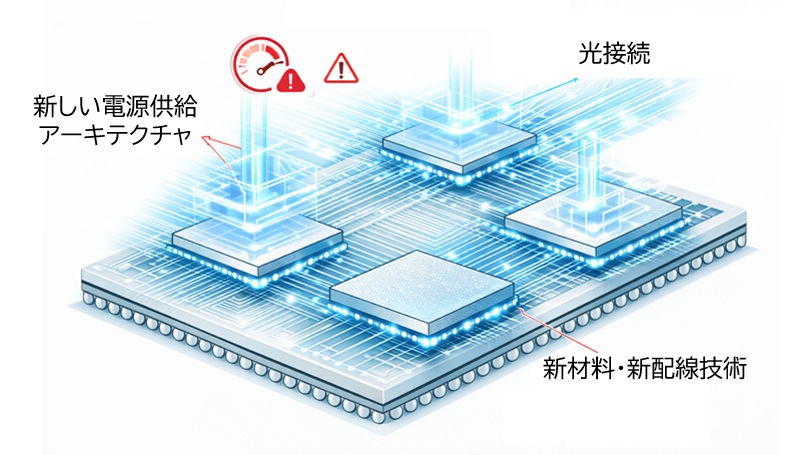
2030年に向けて、AIチップはさらにチップレット化が進むと考えられています。
複数のダイを組み合わせることで、設計の自由度や歩留まりを改善できるためです。
しかし、チップレットが増えるほど、I/O密度と電源供給密度の問題は急速に深刻化します。
複数のチップレットをつなぐためには、膨大な数の信号線と電源ラインが必要になります。
しかし、パッケージ上の配線幅やビア密度には物理的な限界があるため、チップレット数を増やすほど、接続に必要な面積と電力が不足するという構造的な問題が生じます。
さらに、データセンター全体の電力上限はすでに現実的な制約となっています。
AIモデルの巨大化に伴い、1つのAIサーバーが消費する電力は増加し続けていますが、
電力インフラの増強は半導体の進化ほど速く進みません。
その結果、たとえ2nm世代でチップ単体の電力効率が向上しても、データセンター全体の電力需要の伸びを吸収しきれなくなりつつあります。
こうした背景から、2030年のAI半導体では、次のような技術が重要になると考えられます。
- 光接続によるチップ間帯域の抜本的な拡張
- 新しい電源供給アーキテクチャによる電力損失の削減
- 新材料・新配線技術による密度限界の突破
最終的には、どの技術も
「接続密度と電力密度の限界をどう突破するか」
という一点に収束します。
2030年のAIチップ競争は、電力・帯域・配線密度という“物理的制約”をどう乗り越えるかが勝敗を分ける時代になると考えられます。
まとめ (AIチップの勝者を決めるのは何か)
AIチップの勝敗を決めるのは、トランジスタ数ではなく“どれだけ高密度に接続できるか”です。
2nm、HBM、RDL、先端パッケージといった個別技術は、すべて配線密度を高めるための構成要素に過ぎません。
微細化は今後も続きますが、性能を左右するのはロジック・メモリ・パッケージを横断した接続構造の最適化です。
AIチップ性能を決める要素
| 要素 | 役割 | 制約 | 技術例 |
| ロジック密度 | 演算性能 | 配線混雑 | GAA, BSPDN |
| メモリ接続密度 | 帯域 | TSV, 発熱 | HBM |
| パッケージ配線密度 | システム性能 | 歩留まり | RDL, CoWoS |

