

近年のAIブームやクラウドサービスの拡大により、コンピュータの計算基盤は大きく変化しています。
かつてはCPUが「万能の頭脳」として計算処理を一手に担っていましたが、現在はGPUやTPUといった用途特化型プロセッサが急速に存在感を増しています。
このコラムでは、CPU・GPU・TPUについて、違いや歴史を振り返り最新動向と2035年までの将来の展望、さらにTPUに続く次世代PUの構想を解説します。
CPU・GPU・TPUの特徴・用途
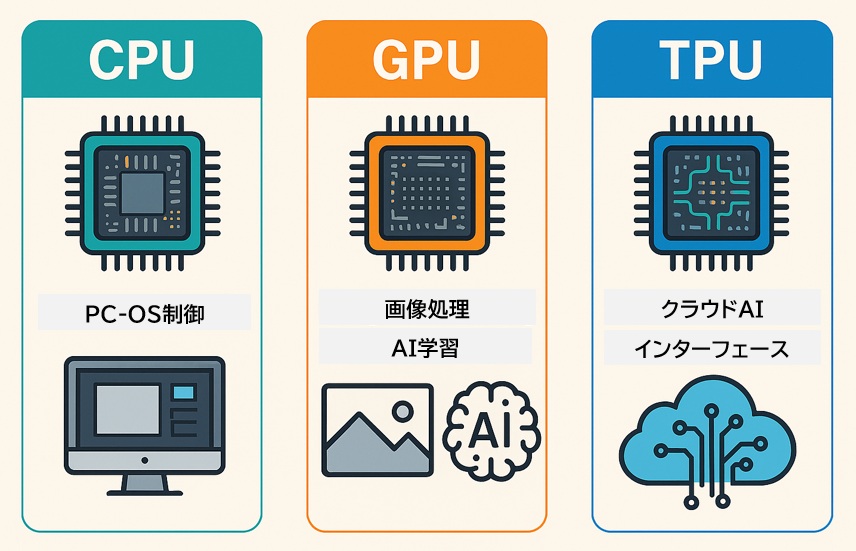
コンピューティングの現場では、処理内容に応じて「CPU」「GPU」「TPU」を使い分けることが重要です。
それぞれの特徴と用途を理解することで、最適なシステム設計や処理効率の向上につながります。
<各プロセッサの比較表>
| 区分 | 特徴 | 主な用途 | 強み | 弱み |
| CPU | 汎用プロセッサ(Central Processing Unit) | OS制御、一般的なアプリケーション処理 | 幅広い処理に対応できる汎用性 | 並列処理が苦手で、処理速度に限界がある |
| GPU | 大量並列演算に特化(Graphics Processing Unit) | 画像処理、AIの学習フェーズ | 数千〜数万の演算ユニットによる高並列性能 | 消費電力が大きく、用途が限定される |
| TPU | Googleが開発したAI専用プロセッサ(Tensor Processing Unit) | 機械学習の推論・学習(特にTensorFlow) | 行列演算に最適化されており、AI処理に特化 | 汎用性が低く、特定用途にしか使えない |
- CPUは「何でもできる司令塔」
→ OSの制御やアプリの実行など、全体のバランスを見ながら処理を行う中心的存在。 - GPUは「力仕事に強い演算職人」
→ 同じ処理を大量に並列でこなすのが得意。画像処理やAIの学習など、膨大な演算が必要な場面で活躍。 - TPUは「AI専用のスペシャリスト」
→ 特定のAI処理(特に行列演算)に特化して設計されており、TensorFlowなどのフレームワークと相性が良い。
(※TensorFlow(テンソルフロー)とは、Googleが開発したオープンソースの機械学習ライブラリで、PyTorchやKerasと並ぶ主要なディープラーニングフレームワークの一つです。特にディープラーニング(深層学習)に強く、画像認識・自然言語処理・音声認識など、AI分野の多くのタスクに活用されています。)
AIや画像処理では、同じ演算を何千回も繰り返す必要があります。
CPUでは1つずつ順番に処理しますが、GPUやTPUは「同時に大量に処理」できるため、時間短縮につながります。これが「並列処理」の強みです。
歴史的背景と進化の流れ
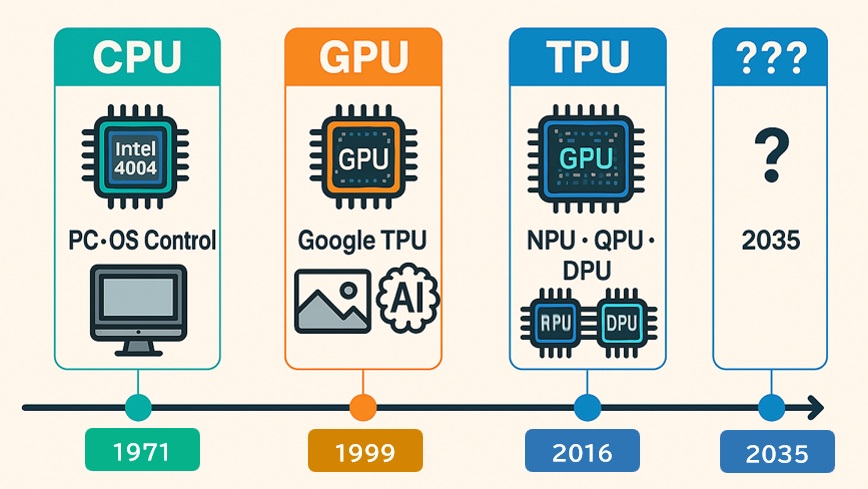
コンピューティング技術は、時代とともに「汎用 → 並列 → 特化」へと進化してきました。
これは単なる性能向上ではなく、処理対象の変化(OS制御 → 画像処理 → AI推論)に対応するための必然的な流れです。
技術進化の年表とその意味
| 年代 | 出来事 | 技術的意義・背景 |
| 1971年 | Intelが世界初のマイクロプロセッサ「4004」を発表 | CPUの誕生。以降、PCやサーバの中核として、OS制御や汎用アプリケーション処理を担う「司令塔」として進化 |
| 1999年 | NVIDIAがGPU(Graphics Processing Unit)を定義 | 画像処理専用の並列演算ユニットとして登場。2006年にはCUDA技術により「GPGPU(汎用GPU計算)」が可能となり、AIやHPC(高性能計算)分野へ進出 |
| 2016年 | GoogleがTPU(Tensor Processing Unit)を発表 | ディープラーニング専用のハードウェア。行列演算に特化し、AI推論・学習の高速化と省電力化を実現。AI革命の加速に貢献 |
CUDA (Compute Unified Device Architecture)技術とは、NVIDIAが開発したGPUによる並列計算を可能にするプラットフォームおよびAPIのことです。
進化の流れと重要性
CPU(汎用) → GPU(並列) → TPU(特化)
- CPU:あらゆる処理に対応できるが、並列処理には限界がある
- GPU:同じ処理を大量に並列実行することで、画像処理やAI学習に強みを発揮
- TPU:AI処理に特化した設計により、効率と速度をさらに追求
なぜこの流れが重要なのか?
- 技術選定の根拠になる:処理内容に応じて、どのプロセッサを選ぶべきかが明確にできます。
- アーキテクチャ理解の第一歩:ハードウェアの進化は、ソフトウェア設計やシステム構成にも直結します。
(アーキテクチャ(architecture)とは、システムやソフトウェアの構造・設計思想を指します。) - AI時代の基盤知識:TPUの登場は、AI技術が「研究用途」から「社会実装」へ移行した象徴となります。
CPU・GPU・TPUの進化と技術トレンド
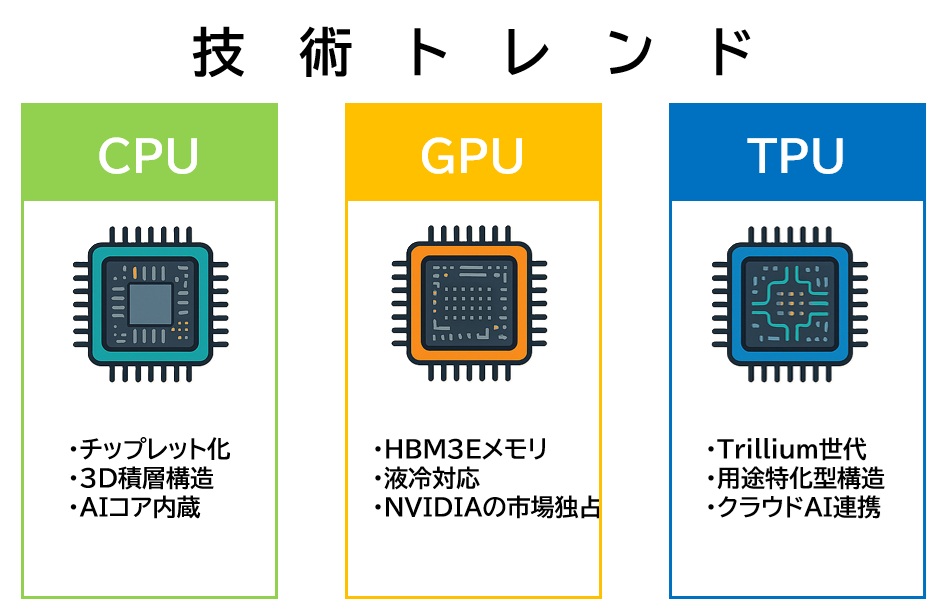
CPU:汎用性を維持しつつ構造革新が加速
- チップレット化:複数の小型チップ(チップレット)を1つのパッケージに統合することで、製造効率・歩留まり・柔軟性が向上
- 3D積層化:複数の回路層を垂直方向に積み重ねることで、通信距離の短縮・処理速度の向上・省電力化を実現
- AIコアの内蔵:従来の汎用CPUにAI専用演算ユニット(NPUなど)を組み込み、推論処理を高速化
GPU:AI需要の爆発でハードウェアが急進化
- HBM3Eメモリ:超高速・高帯域なメモリ技術により、AIモデルの大規模化に対応
- 液冷対応:高発熱化に伴い、冷却技術が進化。データセンターでは液冷が標準化の方向へ
- NVIDIAの市場独占:AI・HPC分野での最適化が進み、CUDAエコシステムの強みも相まって圧倒的なシェアを維持
TPU:AI専用プロセッサとしてクラウド推論に特化
- Trillium世代の登場:Googleが開発した最新TPU。従来比で約10倍の性能向上を達成
(Trillium世代とは、Googleが開発した第6世代TPUのコードネームで、2024年に発表されたAI専用アクセラレータチップです。) - 用途特化型の進化:行列演算に最適化された構造により、AI推論処理を高速・省電力で実行
- クラウドAIでの活躍:Google Cloud上でのAI推論処理に特化し、スケーラブルなAIサービスの基盤として運用中
今後の技術進化
これらの進化は単なる性能向上ではなく、以下のような本質的な変化を示していくと考えられています。
- CPU:汎用性を保ちつつ、AIや並列処理への対応力を強化
- GPU:並列演算の限界突破と冷却・メモリ技術の革新
- TPU:用途特化による効率最適化とクラウド連携の深化
技術課題と解決へのアプローチ
各プロセッサは進化を続けていますが、それぞれに固有の技術的課題があります。
CPUの課題と解決策
主な課題:
- 微細化の限界:トランジスタのサイズが限界に近づき、性能向上が限界に
- 発熱問題:高密度化により熱がこもりやすく、冷却設計が複雑化
- AI性能不足:AI処理には並列性と専用演算が求められるが、従来CPUでは非効率
解決へのアプローチ:
- 3D積層技術:回路を垂直方向に積み重ねることで、通信距離を短縮し、処理効率と冷却性を向上
- ヘテロジニアス構成:CPUにGPUやTPUなどの専用コアを統合し、用途に応じた最適演算を実現(例:Intel Meteor Lakeのチップレット(タイル)構成)
(ヘテロジニアス構成(heterogeneous architecture)とは、異なる種類のプロセッサやコンポーネントを組み合わせて構成されたシステム設計のことです。)
GPUの課題と解決策
主な課題:
- 消費電力の増加:高性能化に伴い、電力効率が課題に
- メモリ帯域の制約:大規模AIモデルでは、メモリ転送がボトルネックになる
- 冷却の難しさ:高発熱により、空冷では限界があり、安定動作が困難
解決へのアプローチ:
- HBM4(High Bandwidth Memory):次世代高帯域メモリで、転送速度と容量を大幅に向上
- 光I/O技術:電気信号の代わりに光で通信することで、帯域と消費電力を改善
- 液冷技術の普及:データセンターでは液冷が標準化し、安定性と冷却効率を両立
TPUの課題と解決策
主な課題:
- 汎用性の低さ:AI推論に特化しているため、他用途には使いづらい
- Google依存:Google Cloud環境でしか使えないケースが多く、導入の自由度が低い
解決へのアプローチ:
- XLA(Accelerated Linear Algebra)最適化:TensorFlowの演算を効率化するコンパイラ技術により、TPUの性能を最大限に引き出す
- クラウド拡張:Google Cloud上でのTPU利用が拡大し、スケーラブルなAI推論基盤として活用が進む
2035年までの展望と「次世代PUの構想」

プロセッサ技術は、単なる性能競争から「用途特化 × 組み合わせ最適化」へと進化しています。
2035年には、CPU・GPU・TPUに加え、さまざまな用途特化型PU(Processing Unit)が登場し、ヘテロジニアス(異種混合)な計算環境が主流になると予測されます。
CPU:制御の中枢としての役割を維持
- 3D積層とAIコア統合が標準化
→ 複雑な制御処理と軽量なAI推論を同時にこなす「効率的な頭脳」として進化 - 周波数向上は頭打ち
→ クロック速度の限界により、今後は分散処理やアーキテクチャの効率化が主軸に
CPUは「万能型」から「制御特化型」へと役割を再定義となり、AIや並列処理は他PUに任せ、全体の統合制御に注力する方向へ。
GPU:高性能演算の主力として進化と課題が並走
- 液冷・浸漬冷却の普及
→ 高発熱化に対応し、安定動作と密度向上を両立 - HBM4・光インターコネクトの採用
→ メモリ帯域と通信速度を飛躍的に向上させ、AIモデルの大規模化に対応 - 消費電力規制と競合の激化
→ 環境負荷への対応と、ASIC/NPUなど用途特化型PUとの競争が新たな課題に
GPUは「汎用並列演算の王者」から「用途選定が必要な高性能PU」へと変化。設計者は性能だけでなく、電力・冷却・用途適合性を考慮する必要があります。
TPU:クラウドAI推論の専用エンジンとして定着
- Google Cloudでの定着
→ AI推論処理に特化したクラウド基盤として広く採用 - 性能は飛躍的に向上
→ Trillium世代などにより、従来比10倍以上の効率化を達成 - Google専用ゆえの制約
→ 他社クラウドやオンプレミス環境では導入が難しく、競合ASICとの争いが続く
TPUは「クラウドAI専用PU」として確立。ただし、導入環境の制約があるため、用途と運用体制に応じた選定が必要。
次世代PUたち:用途特化型の多様化
2035年に向けて、以下のような新たなPU(Processing Unit)が登場・普及すると予測されてます。
| PU名 | 概要 | 主な用途・特徴 |
| NPU(Neural Processing Unit) | AI推論専用チップ | スマホ・IoT機器での省電力AI処理。リアルタイム認識や音声処理に活躍 |
| QPU(Quantum Processing Unit) | 量子演算ユニット | 量子コンピュータの中核。古典PUと連携し、最適化・探索問題などに応用 |
| DPU(Data Processing Unit) | 通信・暗号処理専用 | データセンターでのネットワーク処理を分担。CPU/GPUの負荷軽減に貢献 |
| APU(AI Processing Unit) | 小型AI専用PU | ARグラス、ロボット、IoTデバイスなどでのAI処理に特化。低消費電力設計が鍵 |
| BPU(Biological Processing Unit)[研究段階] | 脳型ニューロモーフィックチップ | 人間脳の構造を模倣したAI演算。超低消費電力で「思考型AI」の実現を目指す |
2035年は「PUの覇権争い」ではなく「組み合わせ最適化の時代」
今後は「どのPUが最強か」ではなく、以下のようなヘテロジニアス構成が主流になります:
CPU(制御)+ GPU(並列演算)+ TPU(AI推論)+ NPU(エッジAI)+ QPU(量子処理)+ DPU(通信処理)…
設計者・技術者に求められる視点は、
- 単一PUの性能だけでなく、組み合わせによる全体最適化
- 用途・環境・電力・コスト・拡張性などを総合的に判断する力
- 各PUの役割と限界を理解し、最適なアーキテクチャを構築する設計力
次世代PU時代を生き抜くために
テクノロジーの進化は「単一プロセッサの性能競争」から「複数PUの協調設計」へとシフトしています。
これからの技術者には、ハードウェアの理解だけでなく、全体最適を見据えた設計力と選定力が求められます。
CPU・GPU・TPUの役割を正しく理解することは、キャリア形成の土台
各PUはそれぞれ異なる目的・構造・強みを持っています。
例えば、CPUは制御・汎用処理、GPUは並列演算、TPUはAI推論に特化し、これらの違いを理解することで、設計判断・技術選定・開発効率が大きく変わります。
「なぜこのPUを選ぶのか?」を説明できる技術者は、現場で信頼される存在となります。
特定のPUだけでなく「複数PUの協調設計」ができる人材が求められる
- 今後のシステムは、CPU+GPU+TPU+NPU+DPU…といったヘテロジニアス構成が主流となり、各PUの役割を理解し、連携・分担・最適化を設計できる力が重要となります。
- 単一技術のスペシャリストよりも、複数技術を橋渡しできるジェネラリストが重宝される時代へ
- 「協調設計」「分散処理」「用途最適化」の視点を持つことで、技術者としての価値が飛躍的に高まります。
AI・量子・エッジ・データセンター:現場に応じたPU選定と最適化が競争力になる
- AI推論にはTPUやNPU、量子計算にはQPU、通信処理にはDPUなど、用途特化型PUが急速に普及
- それぞれの現場で「どのPUを使うべきか」「どう組み合わせるか」を判断できる力が差を生む
- ハードウェアだけでなく、ソフトウェア・API・開発環境との整合性も含めて最適化できる人材が求められる
- 「技術を選ぶ力」は「技術を使う力」よりも重要。選定・設計・運用までを見通せる視点を持ちましょう。
未来を創るのは「理解して使いこなす技術者」
2035年に向けて、PUはますます多様化します。
その中で活躍するのは、単なる知識ではなく「構造を理解し、最適に組み合わせ、現場に落とし込める」技術者です。
まとめ
2025年現在、プロセッサ技術は大きな転換期を迎えています。
2035年に向けて、CPU・GPU・TPUに加え、NPU・QPU・DPUなどの用途特化型PUが実用化され、複数PUが共存・協調する時代が本格的に到来します。
本コラムが、エンジニアや業界関係者への参考となれば幸いです。

