

2026年、AIインフラの中心に位置するメモリ技術は大きな転換点を迎えています。
これまでHBM(High Bandwidth Memory)は、GPUやAIアクセラレータの性能を左右するボトルネックとして注目されてきました。
そして、最新世代のHBM4 が登場し、その制約はさらに引き上げられようとしています。
生成AIの高度化、データセンターの大規模化、そしてAI計算需要の爆発的な増加により、メモリ帯域はこれまで以上に重要な役割を持ちます。
HBM4は、AIインフラの性能基準そのものを更新する役割となっています。
本コラムでは、「性能」「供給」「勝者」「AI性能への影響」「サプライチェーン」 の5つの視点から、HBM4の本質とそのインパクトをわかりやすく解説をしていきます。
関連記事:HBMはなぜ“足りない”のか ― 需給逼迫の裏にある「製造+性能」限界の宿命
HBM4は何がどれだけ速くなるのか
HBM4は、AI向けメモリとしてこれまでで最も大きな性能向上を実現します。
特に重要なのは、データをやり取りする速度(帯域幅)が大幅に向上している点です。
AIの計算では、GPUがどれだけ高性能でも、メモリからデータが届くのが遅いと処理が止まってしまいます。
それゆえに、HBM4の帯域向上は、AI全体の処理速度を上げるための重要課題と言えます。
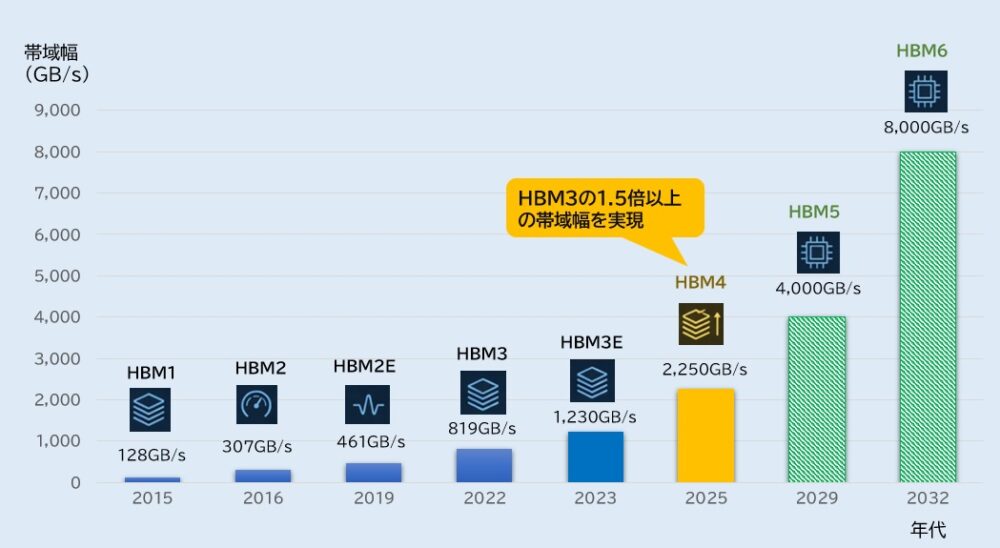
HBM世代別 比較一覧表(速度・帯域・I/O・容量)
| 世代 | 年代 | データレート(Gbps) | I/O幅 | 1スタック帯域 | 1スタック容量 | 備考 |
| HBM1(初代) | 2015 | 約 1.0 | 1024-bit | 約 128 GB/s | 4 GB | 初代HBM。 AMD Fijiで採用。 |
| HBM2 | 2016 | 2.4 | 1024-bit | 約 307 GB/s | 8 GB | JEDEC標準化。 |
| HBM2E | 2019 | 3.6 | 1024-bit | 約 461 GB/s | 24 GB | 帯域・容量が大幅増。 |
| HBM3 | 2022 | 6.4 | 1024-bit | 約 819 GB/s | 24〜36 GB | AIブームを支えた世代。 |
| HBM3E | 2023 | 9〜10 | 1024-bit | 約 1.23 TB/s | 48 GB | HBM3の高速版。あなたの提示値と一致。 |
| HBM4 (現行) | 2025 | 12〜13 (推定)/標準 8〜10 | 2048-bit | 2.0〜2.5 TB/s | 36〜64 GB | I/O幅が2倍に拡張。帯域は1.5倍以上。 |
| HBM5 (予測) | 2029 | 8〜10 (冷却制約で頭打ち) | 4096-bit | 4.0 TB/s | 約 80 GB | 液浸冷却が本格導入。 |
| HBM6 (予測) | 2032 | 16 | 4096-bit | 8.0 TB/s | 96〜120 GB | ガラスインターポーザ・マルチタワー構造。 |
関連記事:液浸冷却の現在と2035年予測:AIサーバーの「熱の壁」突破
関連記事:ガラス基板(Glass Core)供給網の全貌と実用化の壁
帯域幅は前世代比で約1.5倍
HBM4では、1ピンあたりの転送速度が大きく向上し、メモリ全体として扱えるデータ量が増えています。
- HBM3E:およそ 9〜10Gbps
- HBM4:およそ 12〜13Gbps
- 増加率:およそ 1.3〜1.4倍
- スタック全体の帯域:最大で約1.5倍以上
※「Gbps」は、1秒間に何十億ビットのデータを送れるかを示す単位です。
数字が大きいほど、GPUにデータを高速で供給できます。
AIモデルの巨大化に対応する進化
近年のAIモデルは、数百億〜数兆パラメータ規模へと急速に拡大しています。
モデルが大きくなるほど、必要なデータ量も増え、メモリ帯域が不足しやすくなります。
HBM4はこの課題に対し、
- データ供給の遅延を減らす
- GPUの演算ユニットをフル稼働させる
- 学習・推論の効率を高める
といった効果をもたらします。
特に、GPUが持つ膨大な演算回路が“待ち時間”で止まってしまう現象を抑えられる点は、AIインフラにとって非常に大きなメリットです。
HBM4はAIインフラの基準値を引き上げる
AIモデルが今後さらに巨大化することを考えると、メモリ帯域はますます重要な要素になります。
HBM4は、
- AIの処理速度
- 電力効率
- 大規模モデルの扱いやすさ
HBM4がAIインフラの「基準値」を引き上げることが明確になりました。
次に重要となるのは、「HBM4を誰が安定して作れるのか」という供給の問題です。
どの企業がHBM4を量産できるのか
HBM4は、AI向けメモリの中でも特に製造難易度が高い製品です。
そのため、量産できる企業は世界でも限られており、事実上 3社による寡占市場になっています。
HBM4の供給力は、AIインフラ全体の成長スピードを左右するため、どの企業がどこまで量産できるのかは非常に重要なテーマです。
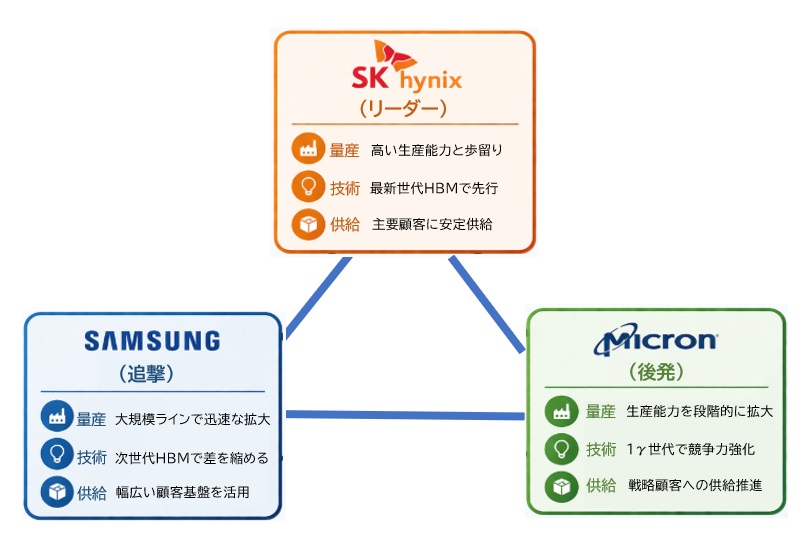
HBM4を製造できるのは世界で3社のみ
HBM4は、複数のメモリチップを縦に積み重ね、数千本規模の微細な配線で接続する高度な技術を必要とします。
この工程には、
- TSV(シリコン貫通電極)
- 高密度再配線
- ハイブリッドボンディング
- 熱管理を考慮したパッケージ構造
など、複数で難関なプロセスが含まれます。
そのため、量産できる企業は以下の3社に限られます。
● SK hynix(韓)
- HBM3Eで高い歩留まりを確立し、HBM市場でトップシェア
- HBM4でも早期量産に向けて最も進んでいるとされる
- AI向けメモリの主力サプライヤーとしてNVIDIAとの関係が強い
● Samsung Electronics(韓)
- 大規模な生産能力を持ち、HBM4の量産開始を早期に発表
- 自社のロジック・パッケージ技術との統合が強み
- 歩留まり改善のスピードが市場の注目点
● Micron Technology(米)
- HBM3Eで追随し、HBM4は2026〜2027年に本格量産が見込まれる
- 北米企業としてサプライチェーンの多様化に貢献
- 製造能力よりも品質・安定性を重視する戦略
HBM4の量産が難しい理由
HBM4は、前世代よりも配線密度が高く、接続点の数も増加しています。
例えば、1スタックあたりの接続数は数千〜1万点規模に達し、1つでも不良があると製品全体が使えなくなるため、歩留まりの確保が極めて難しくなります。
さらに、
- チップ同士を直接接合するハイブリッドボンディング
- 微細なTSVの形成精度
- 熱を逃がすためのパッケージ構造
など、複数の工程が互いに影響し合うため、製造ライン全体の最適化が必要です。
この複雑さが、HBM4を量産できる企業が限られる理由です。
量産能力が「市場の勝者」を決める
AI向けGPUは、HBMを搭載しなければ性能を発揮することはできません。
つまり、HBMの供給が不足すると、GPUそのものが出荷できなくなるということです。
そのため、
- どの企業がどれだけHBM4を供給できるか
- 歩留まりをどれだけ改善できるか
- パッケージ工程をどこまで最適化できるか
HBM4を量産できる企業が限られていることは、AIインフラの成長スピードを左右します。
では、そのHBM4が実際にAI性能へどれほど影響するのか。
ここを理解することが、とても重要です。
HBM4はAI性能にどれだけ影響するのか
GPUは膨大な演算能力を持っていますが、メモリからデータが届くのが遅いと、その能力を十分に発揮できません。
HBM4は、この“データ待ち”の時間を大幅に減らすことで、AIシステム全体の効率を高めます。
AI性能を左右するのは「演算性能 × メモリ帯域」
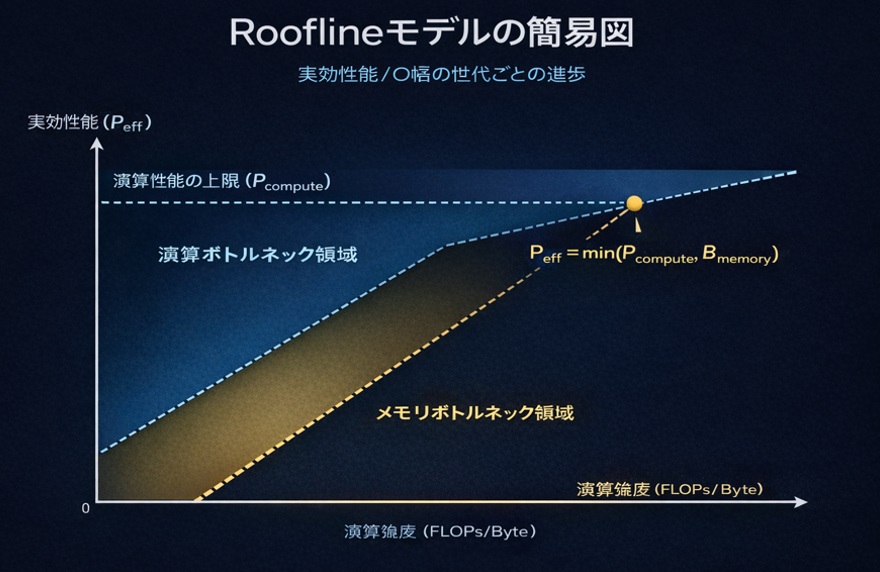
AIモデルの処理速度は、単にGPUの演算性能だけで決まるわけではありません。
実際には、以下の式で表されることが多いです。
実効性能=min(演算性能, メモリ帯域)
「実効性能は、演算性能とメモリ帯域のうち “小さい方” によって決まる」
つまり、どれだけ高性能なGPUを使っても、メモリ帯域が不足していれば性能は頭打ちになります。
HBM4は、このボトルネックであるメモリ帯域を大きく押し上げることで、GPUの潜在能力を引き出す役割を果たします。
学習(トレーニング)での効果
大規模モデルの学習では、膨大なデータをGPUに送り続ける必要があります。
HBM4の帯域向上により、以下のような改善が期待できます。
- 学習時間の短縮
データ供給が速くなるため、GPUクラスタ全体の稼働率が上がります。 - 並列学習の効率向上
モデルを複数GPUで分担する際の通信・同期がスムーズになります。 - 巨大モデルの扱いやすさ向上
100B〜1Tパラメータ級のモデルでも、帯域不足による停滞が起きにくくなります。
特に、学習時間が数週間〜数ヶ月に及ぶ大規模プロジェクトでは、HBM4の効果は非常に大きくなります。
推論(インファレンス)での効果
推論では、ユーザーからの入力に対してAIがどれだけ速く応答できるかが重要です。
HBM4は以下の点で貢献します。
- レスポンス速度の向上
LLMの応答がより滑らかになり、待ち時間が短縮されます。 - マルチモーダル処理の安定化
画像・音声・テキストを同時に扱うモデルでも遅延が発生しにくくなります。 - 高負荷環境での性能維持
同時アクセスが増えても、帯域不足による性能低下が起きにくくなります。
特に、生成AIサービスやリアルタイム処理が求められるアプリケーションでは、HBM4の効果が直接ユーザー体験に反映されます。
電力効率(Perf/W)の改善
HBM4は、AIの電力効率にも影響します。
GPUがデータ待ちで停止する時間が減るため、同じ電力でより多くの処理が可能になります。
- データセンターの電力コスト削減
- 冷却負荷の軽減
- AIインフラの持続可能性向上
AIデータセンターの電力消費が世界的な課題となる中で、HBM4の効率向上は社会的にも重要な意味を持ちます。
次世代GPUはHBM4を前提に設計されている
NVIDIA、AMD、Intelなどの主要GPUメーカーは、次世代アクセラレータをHBM4前提で設計しています。
HBM4がAI性能を大きく押し上げることは分かりました。
しかし、性能が高いほど必要量も増えます。
そこで避けて通れないのが「HBM不足」という現実です。
AIの進化を支えるには、供給が追いつくかどうかが重要になります。
HBM不足は解消されるのか
HBM4の登場によってメモリ性能は大きく向上しましたが、供給面の課題は依然として深刻です。
AI向けGPUはHBMを搭載しなければ出荷できないため、HBMの供給量はAIインフラ全体の成長スピードを左右します。
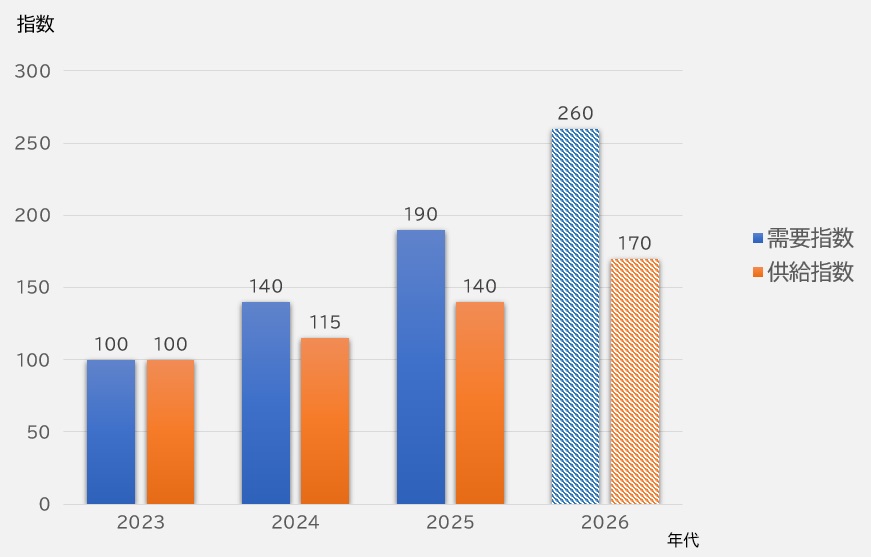
2023〜2025年にかけて続いた「HBM不足」は、2026年に入っても完全には解消しないと予想されます。
需要は 指数関数的に増えている
HBM不足が続く最大の理由は、AI需要の伸びが想定を大きく上回っているためです。
● 需要増の主な要因
- 生成AIの普及:LLMや画像生成モデルの利用が急増
- モデルの巨大化:100B〜1Tパラメータ級が標準化
- データセンターの建設ラッシュ:世界中でAI専用施設が増加
- GPUの高性能化:1基あたりのHBM搭載量が増加(例:数十GB → 数百GBへ)
特に、次世代GPUはHBM4を複数スタック搭載するため、1台のGPUが必要とするHBM量が増えています。
その結果、HBMの需要は年率30〜40%以上で増加していると推定されます。
供給が追いつかない理由
HBM4は性能が高い一方で、製造難易度が非常に高く、供給量を増やすには時間がかかります。
● 供給が増えにくい主な要因
- 歩留まりの改善に時間がかかる
→ HBM4は接続点が多く、1つの欠陥で製品全体が不良になる - ハイブリッドボンディング装置の供給が限られる
→ 製造装置そのものがボトルネック - TSV材料・薬液などのサプライチェーンが逼迫
→ 材料メーカーの増産にもリードタイムが必要 - クリーンルームの増設が追いつかない
→ メモリ工場の拡張には数千億円規模の投資と数年の期間が必要
これらの要因が重なり、HBM4の供給は急激に増やすことができません。
2026年も需給は、タイトなまま
HBM4の量産が始まったことで供給能力は確実に増えていますが、需要の伸びがそれを上回っています。
そのため、2026年時点でも以下の状況が続くと見られます。
- GPUメーカーはHBMの確保が最優先課題
- データセンターの建設計画がHBM供給に左右される
- AIサービスの拡張スピードが制約される可能性
- HBM価格は高止まりしやすい
HBM4の需要が急増する一方で、供給が追いつかない背景には、製造の難しさがあります。
この“難しさ”こそが、実は装置メーカー・材料メーカーにとって大きな追い風となっています。
HBM4の裏側には、支える産業の存在があります。
HBM4の量産化で需要が高まる装置・材料企業
HBM不足は2026年時点でも続く見通しですが、永続的な問題ではありません。
メモリメーカー各社は2026〜2027年にかけて新ラインの立ち上げや設備投資を進めており、歩留まり改善も徐々に進行しています。
ただし、HBM4は製造難易度が高く、供給が需要に追いつくのは早くても2027年後半〜2028年と見られています。
特に、ハイブリッドボンディング装置やTSV材料などのサプライチェーンがボトルネックとなっているため、完全な需給緩和には時間がかかります。
つまり、短期的には“タイトな状況が続く”ものの、中期的には増産効果が現れ、徐々に改善へ向かう流れが期待できます。
HBM4は、超高難度プロセスの集合体
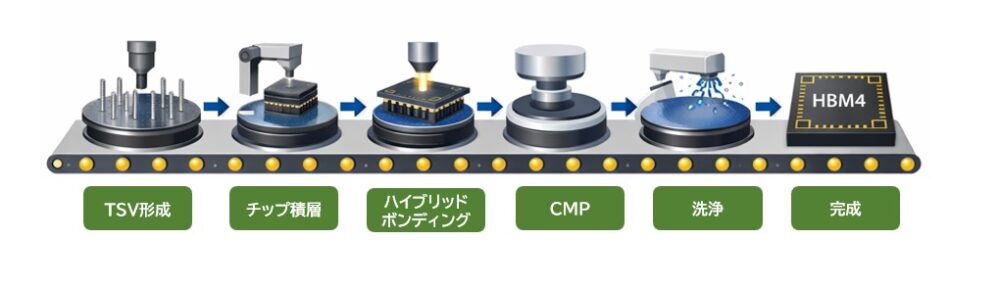
HBM4は、複数のメモリチップを縦に積み重ね、数千〜1万点規模の微細な接続で結びつける構造を持ちます。
この構造を実現するためには、以下のような高度な工程が必要です。
- TSV(シリコン貫通電極)形成
- 高密度再配線(RDL)
- ハイブリッドボンディング
- 高精度CMP(研磨)
- 高純度洗浄プロセス
- 熱を逃がすためのパッケージ材料
これらの工程は、従来のDRAMよりもはるかに厳しい精度と品質が求められます。
装置メーカーが需要を受ける理由
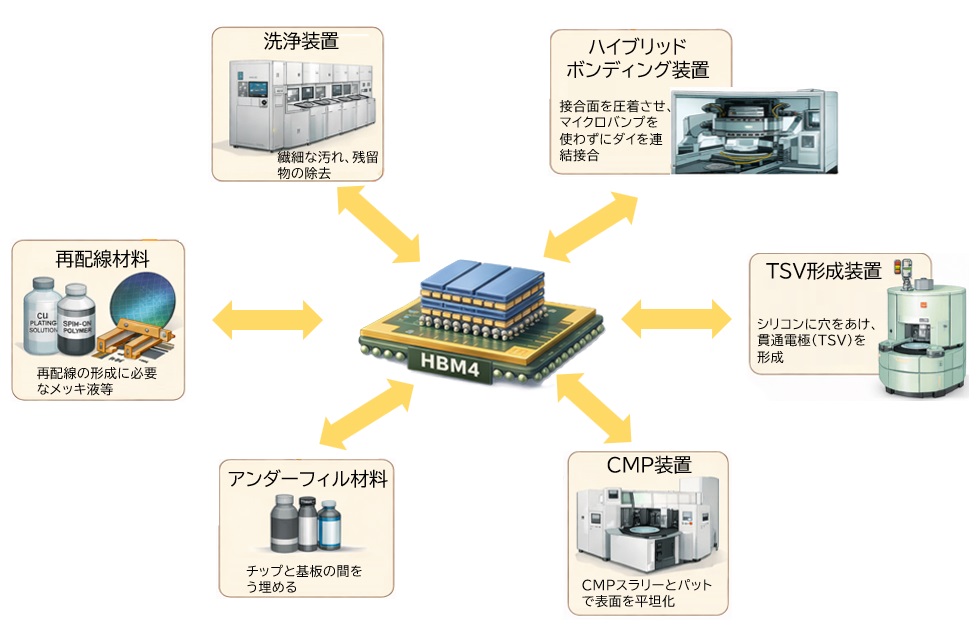
HBM4の製造では、工程ごとに専用の装置が必要になります。
特に需要が増えるのは次の領域です。
● ハイブリッドボンディング装置
HBM4では、チップ同士を直接接合する「ハイブリッドボンディング」が主流になります。
この装置は世界的に供給が限られており、HBM4の増産に伴って需要が急増します。
- 用途:チップ間の高密度接続
- 重要性:歩留まりを左右する最重要工程
● TSV形成装置
HBMの特徴である“縦方向の配線”を作るための装置です。
微細な穴をシリコンに貫通させ、金属で埋める工程は非常に難易度が高く、専用装置が不可欠です。
● CMP(研磨)装置
積層したチップの表面を均一に整えるために使用されます。
HBM4では層数が増えるため、CMPの重要性がさらに高まります。
● 洗浄装置
微細加工では、わずかな汚れでも不良につながるため、洗浄工程が増えます。
HBM4では洗浄回数が従来よりも多く、洗浄装置の需要が伸びます。
材料メーカーが需要を受ける理由
HBM4の製造には、従来よりも高性能な材料が必要になります。
● 再配線材料(Cu・絶縁膜)
配線密度が高くなるため、低抵抗・低誘電率の材料が求められます。
● アンダーフィル材料
積層チップの隙間を埋め、熱や応力を吸収する材料です。
HBM4では熱密度が高くなるため、耐熱性の高い材料が必要です。
● 高純度薬液・スラリー
TSV形成やCMP工程で使用される薬液は、微細加工に対応した高純度品が求められます。
HBM4は、装置・材料産業全体を押し上げる技術
HBM4の普及は、メモリメーカーとともに、装置メーカー・材料メーカーの方が長期的な成長機会を得やすいとも言えます。
その理由は、
- HBM4は製造工程が多い
- 工程ごとの難易度が高い
- 歩留まり改善に装置・材料の品質が直結する
HBM4は単なるメモリ技術ではなく、産業全体を押し上げる力を持つ存在です。
最後に、HBM4がもたらす本質的な変化と、これからのAIインフラにとって何を意味するのかをまとめます。
まとめ
HBM4の普及は、AIインフラの現在を変えるだけではありません。
これから数年の間に、AIの設計思想そのものを大きく変えていく可能性があります。
2027年以降には、HBM4を前提としたGPUやAIチップが主流となり、モデルの巨大化はさらに加速します。
これにより、1兆パラメータ級のモデルが一般的なクラウド環境で扱えるようになり、AIの応答速度や処理能力は今よりも大幅に向上します。
また、HBM5・HBM6の登場によって、AIは「より速く・より大きく」だけでなく、「より省電力で・より身近に」進化していきます。
データセンターだけでなく、エッジ機器やロボット、車載AIなど、あらゆる領域で高度なAIが当たり前に動く世界が見えてきます。
HBM4は、その未来への“最初の大きなステップ”と言える存在といえるでしょう。
