


はじめに
本連載「AI半導体の変質と『密度』の衝撃」も、いよいよ最終回となりました。
これまで第1回から第5回にかけて、AIチップの進化を妨げる要因を、配線密度・電力密度・熱密度・I/O密度・設計複雑度密度という5つの視点から掘り下げてきました。
かつての半導体競争は、トランジスタをどこまで微細化し、クロックをどれだけ上げられるかという“単線的な進化”で語ることで進化してきました。
しかし、2030年のAI半導体は、もはや単一の技術だけでは限界が予想されます。
- 微細化のパラドックス:2nm以降は配線抵抗が増え、微細化のメリットが相殺されます。
- エネルギーの壁:1,000W級GPUの登場により、データセンター側の電力供給と冷却が限界に近づきます。
- 構造的転換:性能を決めるのは、チップ単体からHBMやCoWoSなどの先端パッケージへ移行しています。
最終回となる本コラムでは、これら個別のテーマを統合し、2030年のAI半導体産業がどのような「構造」に収束していくのかを解説します。
●本コラムは連載の第6回目(最終回)です。
・第1回:AIチップの2nm競争は“配線密度”で決まる HBM・RDL・BSPDNが変える半導体構造
・第2回:【2026年最新】AI-DCは“電力密度限界”で崩壊かー電力・消費電力・電源設計の本質
・第3回:HBMはなぜ“足りない”のか ― 需給逼迫の裏にある「製造+性能」限界の宿命
・第4回:CoWoSとHBM不足の真因:TSMC・Intel・Samsungの覇権争いと2035年AIパッケージロードマップ
・第5回:2nm設計は「EDA × アーキ × DTCO × パッケージ × 検証」の総合戦争
・第6回:2030年のAI半導体地図 ー 2nm・HBM・パッケージ・電力のすべてが交差する未来(本稿)
微細化の終点 ― 2nm以降は“配線密度”が支配する
半導体の微細化が2nm世代へ進む中で、業界の関心は「より小さなトランジスタを作ること」から、「チップ全体の配線をどう効率化するか」へと大きく移行しています。
これまでは、トランジスタを縮小すればそのまま性能が向上しました。
しかし2nm以降では、トランジスタの性能向上が配線の物理的な限界によって相殺される状況が顕著になっています。
トランジスタ性能を凌駕する「配線抵抗」の衝撃
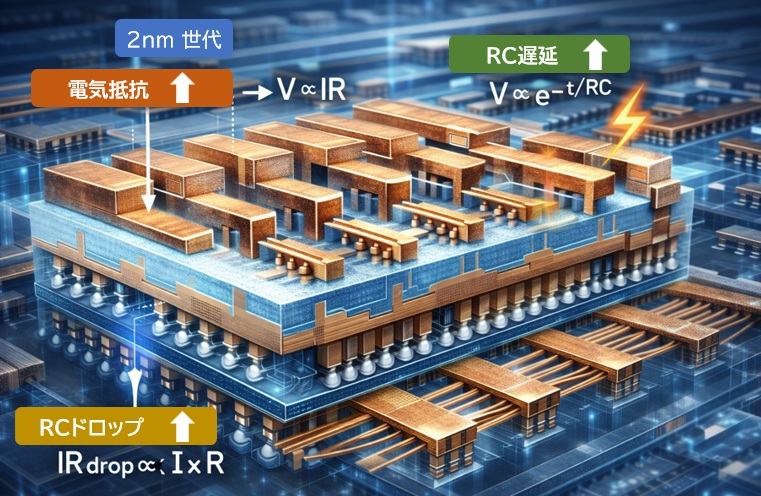
微細化が進むほど、配線は細く長くなり、金属配線の抵抗値は急激に増加します。
その結果、以下のような問題が深刻化します。
- RC遅延:信号が配線を通る際の遅れが増え、動作速度を押し下げます。
- IRドロップ:電源電圧が配線途中で失われ、トランジスタに十分な電力が届きません。
特にIRドロップは、チップ全体のクロック維持を困難にする大きな要因です。
微細化によって配線層が複雑化し、電源がトランジスタに届くまでの距離が長くなることで、電圧降下の影響が無視できなくなっています。
2nmの救世主:BSPDN(裏面電源供給ネットワーク)
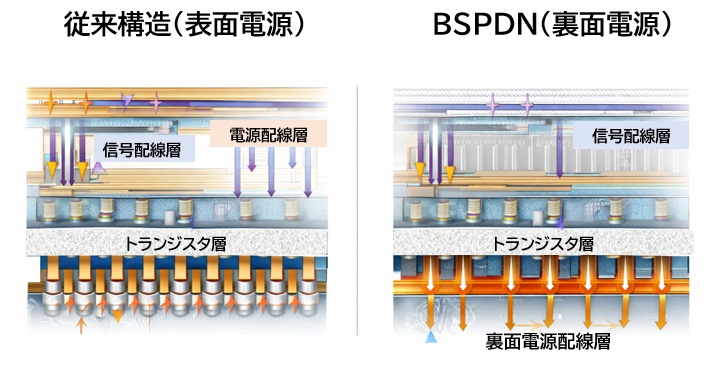
こうした「配線の壁」を突破するために登場したのが BSPDN(Backside Power Delivery Network) です。
従来は、信号線と電源線がトランジスタの上側に混在していました。
BSPDNでは、電源供給網をウェハの裏面に分離することで、構造を根本から見直します。
その効果は大きく、次の3点が特に重要です。
- 配線混雑の緩和:表側の層を信号線に集中でき、配線密度を高くできます。
- IRドロップの低減:トランジスタのすぐ近くから電力の供給ができます。
- 面積効率の向上:電源配線が占めていたスペースが解放され、さらなる高密度化が可能になります。
BSPDNは、2nm以降の性能向上を支える“必須技術”となっています。
「線幅の数字」から「電源構造の最適化」へ
2030年に向けて、TSMC・Samsung・Intelの競争軸は、従来の「○nm」という線幅の数字ではなく、
どれだけ効率的な電源供給構造を実現できるか に移りつつあります。
1.4nmや1nm世代を見据えたとき、配線抵抗による性能低下をどこまで抑え、実効的な配線密度を最大化できるかが、次世代AIチップの性能を決定づける鍵となります。
電力制約 ― AIデータセンターは電力密度で限界を迎える
2030年に向けて、AI半導体の進化を最も強く制約する要因は、演算性能そのものではなく 「電力」 です。
AIモデルの巨大化に伴い、必要となる演算リソースは急増していますが、それを支える電力供給と冷却インフラが限界に近づいています。
1,000W級チップの衝撃と「電力供給の限界」
現在のハイエンドGPUはすでに700W級に達しています。
2030年には、1つのチップで 1,000W(1kW) を消費するGPUが登場すると見込まれています。
これは、家庭用電子レンジをフルパワーで動かし続けるのと同等の電力が、数センチ四方のシリコン上で発生することを意味します。
その結果、データセンター側では次のような問題が顕在化します。
- ラック電力の逼迫:従来のラックあたり30〜60kWという電力上限では、搭載できるAIチップ数が物理的に制限されます。
- IRドロップの増大:チップ内部の電源プレーンで電圧降下が発生し、安定動作が難しくなります。
電力供給の限界は、AIインフラ全体の拡張スピードを左右する重大なボトルネックとなっています。
冷却技術のパラダイムシフト:空冷から液冷・浸漬冷却へ

電力密度の増大は、同時に 熱密度の爆発 を引き起こします。
従来の空冷方式では、1,000W級の熱を排出することは物理的に不可能です。
そのため、冷却技術は次の段階へと移行しています。
- 液冷(Liquid Cooling)の標準化
チップに直接冷却水を循環させる「コールドプレート方式」が、ハイエンドサーバーの標準仕様となります。 - 浸漬冷却(Immersion Cooling)の普及
サーバー全体を絶縁性の液体に沈める方式で、冷却効率が飛躍的に向上します。
冷却技術は、もはや“周辺設備”ではなく、AI半導体の性能を左右する中核技術となっています。
電力密度が“アーキテクチャの前提条件”に
これまでのチップ設計は「性能を最大化する」ことが出発点でした。
しかし2030年のAI半導体は、許容される電力密度の範囲で、いかに効率を引き出すか という逆算の設計思想が不可欠になります。
- 低消費電力で高効率を実現する ドメイン特化型アーキテクチャ(DSA)
- BSPDNなどによる 電力損失の最小化
- 電力・熱を前提にした システム全体の最適化
電力密度を制御できる企業こそが、2030年のAIインフラを支える主役となるでしょう。
メモリ壁 ― HBM4/5でも帯域は足りない
AIモデルの規模が急速に拡大する中で、演算器(ロジック)の処理能力と、メモリからデータを供給する速度の差、いわゆる 「メモリ壁(Memory Wall)」 がこれまで以上に深刻化しています。
どれだけ演算性能を高めても、メモリがデータを十分な速度で供給できなければ、AIチップ全体の性能は頭打ちになります。
HBM4/5が直面する物理的限界
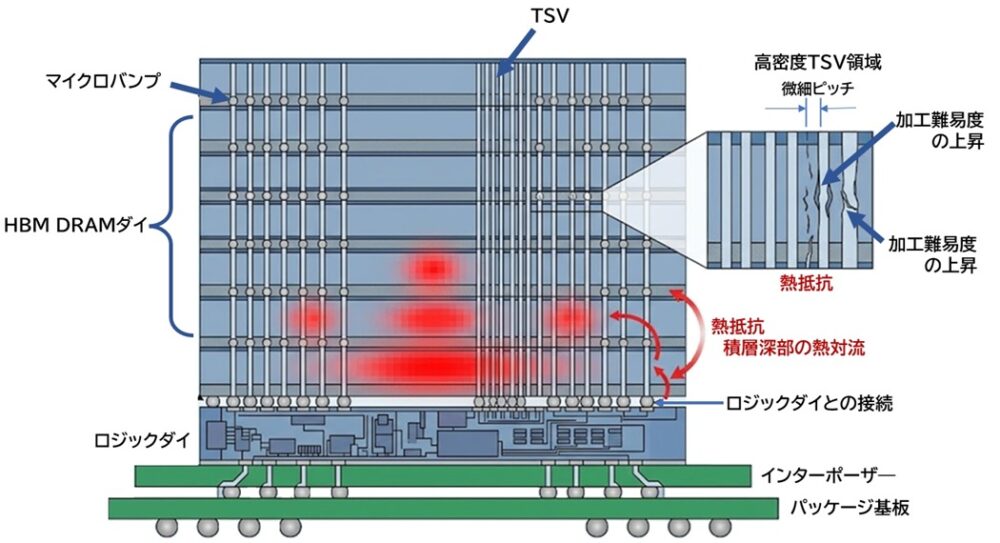
広帯域メモリとしてAIチップを支えてきたHBMは、HBM4、HBM5へと進化を続けています。
しかし、その先には避けられない物理的な壁が存在します。
- TSV(シリコン貫通電極)の限界
TSVをさらに高密度化するには加工精度が極めてシビアになり、歩留まりやコストが急激に悪化します。 - 熱密度の悪化
DRAMの積層数が増えるほど、深部の熱が逃げにくくなり、データ保持エラーや性能低下となります。 - ロジックとの性能ギャップ拡大
ロジック半導体は微細化で性能が伸び続ける一方、DRAMは物理限界に近づき微細化が停滞します。
HBMは依然として重要ですが、HBMだけでAIモデルの帯域要求を満たすことは、2030年には難しくなるでしょう。
「階層化メモリ」への構造転換

こうした状況を踏まえ、2030年のAIチップは 単一のメモリ規格に依存しない構造 へと移行します。
鍵となるのは、複数のメモリを役割ごとに組み合わせる 階層化アーキテクチャ です。
- HBM4/5:第1層(最速・最頻アクセス)
演算器に最も近い“超高速キャッシュ”として機能。 - CXLメモリ:第2層(大容量・中速)
外部メモリを高速・低遅延で接続し、システム全体のメモリ容量を拡張。 - 高密度NAND:第3層(大容量・低速)
チェックポイント保存や巨大データセットの待機場所として統合。
このように、メモリ不足を「帯域だけで解決する」のではなく、スピードと容量を階層で分担する“システム設計”で解決する のが2030年の標準となると予想されます。
パッケージ主役化 ― CoWoS以降の覇権争い
AI半導体の性能を左右する主役は、もはやシリコンウェハ上の微細化(前工程)だけではありません。
2030年に向けて、複数のチップを1つのパッケージに統合する 先端パッケージング技術 が、事実上「前工程と同等の重要性」を持つようになっています。
パッケージは単なる“入れ物”ではなく、AIチップの性能・コスト・歩留まりを決定づける中心技術へと変わりました。
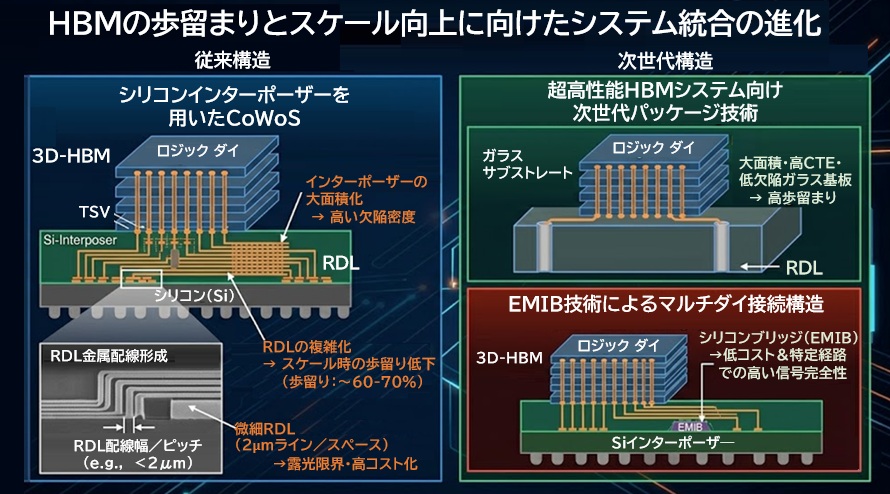
「CoWoS」の限界と次世代への移行
現在、NVIDIAのGPUなどを支える代表的な技術が CoWoS です。
AIチップのデファクトスタンダードとして広く採用されていますが、2030年に向けて次の課題が顕在化しています。
- 大面積化による歩留まり悪化
チップレット数の増加に伴い、巨大なインターポーザの歩留まりが低下傾向となります。 - RDL(再配線層)の微細化限界
チップ間を結ぶ配線密度をさらに高めるには、従来のRDL技術は限界に近づきます。 - 素材の転換期
有機基板では平坦度や微細配線に限界があり、シリコンインターポーザ や ガラス基板 への移行が本格的に動き出しています。
CoWoSは依然として強力ですが、2030年のAIチップを支えるには、より高密度・高効率な次世代パッケージ技術が不可欠になります。
先端パッケージを巡る3大巨頭の攻防
パッケージング技術は、ファウンドリ各社の戦略を大きく左右する“差別化ポイント”になっています。
- TSMC
CoWoSの進化版に加え、3D積層技術 SoIC を推進。
ロジック同士、ロジックとメモリを垂直方向に積層し、究極の高密度実装を目指します。 - Intel
EMIB(高密度ブリッジ)や Foveros(3D積層)を武器に、柔軟なチップレット構成を実現。
異なるプロセスノードのチップを自由に組み合わせられる点が強み。 - Samsung
I-Cube シリーズを中心に、メモリ・ロジック・パッケージを垂直統合で提供。
自社メモリとの組み合わせで、システム全体の最適化を図ります。
各社が競うのは、単に“高性能なパッケージ”ではなく、
どれだけ効率よく異種チップを統合し、1つのシステムとして機能させられるか という総合力となります。
「パッケージを制する者がAIを制する」時代へ
2030年のAI半導体における競争軸は、チップ単体の性能ではなく、
ロジック・メモリ・通信チップをどう統合し、システムとして最大性能を引き出すか に移っています。
先端パッケージングは、AIチップの性能・コスト・供給能力を左右する“最大の戦場”となり、
パッケージ技術を制した企業がAI市場の主導権を握る時代が到来すると予想されます。
設計複雑度の爆発 ― 2nm時代のEDAと人材不足
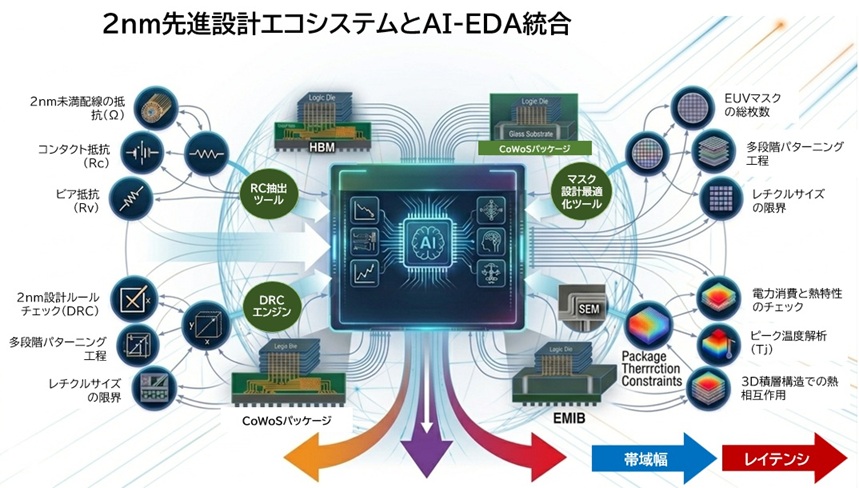
2nmプロセス以降のチップ設計は、従来の延長線では対応できないほど複雑化しています。
微細化が進むほど設計上の制約は指数関数的に増え、わずかな変更が歩留まりや性能に大きく影響するようになりました。
もはや、人間が手作業で全体を把握しながら設計することは限界に近づいています。
2nm設計を阻む「計算量の壁」
微細化に伴う設計難易度の上昇は、開発現場に次のような負荷をもたらしています。
- マスク枚数と工程の増加
微細パターニングを維持するために必要なマスク枚数が増え、マルチパターニングの最適化が設計期間を圧迫。 - 配線最適化の難易度上昇
配線抵抗を抑えるためのルーティング計算が極めて複雑化。 - EDAツールの計算量爆発
これら膨大な制約を満たすためのシミュレーションに必要な計算リソースが急増し、設計コストを押し上げます。
2nm世代では、設計そのものが“巨大な計算問題”となり、EDAツールの性能がチップ開発のボトルネックになりつつあります。
AIによるEDAの自動化と「人間」の課題
この状況を打開するため、SynopsysやCadenceなどのEDAベンダーは、AIを組み込んだ設計ツールの開発を加速しています。
AIがレイアウトや配線ルートを自動で最適化することで、設計期間の短縮が期待されていますが、一方で新たな課題も浮上しています。
- 高度なスキルを持つ設計者の不足
AIツールを使いこなしつつ、物理設計からシステム全体まで理解できる人材が不足。 - 設計コストのさらなる上昇
先端EDAツールのライセンス料、長期化する開発期間、専門人材の確保などにより、
1チップあたりの開発費は数億ドル規模に達するでしょう。
2030年のAI半導体開発では、AI駆動型EDAをどれだけ活用し、限られた人材をどう配置するかが、企業の競争力を左右する重要なポイントになります。
地政学リスク ― 2030年の供給網はどう変わるか
AI半導体は、もはや単なる工業製品ではなく、国家の競争力や安全保障に直結する「戦略物資」として扱われるようになりました。
2030年に向けて、半導体サプライチェーンは技術的な進化だけでなく、地政学的な力学によって大きく形を変えています。
「特定地域依存」からの脱却と多極化
長年、世界の先端半導体製造は台湾、特にTSMCに大きく依存してきました。
しかし、地政学的な緊張の高まりを背景に、2030年の供給網は「集中」から「分散」へと明確にシフトしています。
- 台湾リスクとTSMCのグローバル展開
台湾有事の懸念を受け、TSMCは米国・欧州・日本へと製造拠点を分散。
有事でも供給を維持できる“レジリエンス(回復力)”の確保が進みます。 - 米中分断による二重構造化
米国の対中輸出規制と、中国の内製化加速により、サプライチェーンは事実上「二つの陣営」に分かれつつあります。 - 日本・韓国・ASEANの役割再定義
日本のRapidus、韓国勢の強化、ASEANの後工程拠点化など、製造ネットワークは多極化へ向かうでしょう。
供給網は「効率最優先」から、「リスク分散と信頼性重視」へと価値基準が変わりつつあります。
先端パッケージング拠点の重要性
2030年の地政学において、前工程(ウェハ製造)以上に注目されるのが 先端パッケージングの所在地 です。
- 最終工程を握るリスク
前工程を分散しても、パッケージングが特定地域に集中していれば、供給網の脆弱性は残ります。 - 地産地消型サプライチェーンの台頭
輸送リスクやリードタイムを削減するため、
ロジック製造・メモリ製造・先端パッケージングを同一地域または同盟国内で完結させる動きが加速するでしょう。
パッケージングは、技術面だけでなく、地政学的な観点からも極めて重要な位置づけとなっています。
「技術の壁」と「国境の壁」の交差点
2030年の供給網は、単に効率を追求する時代から、
信頼性・安全保障・リスク分散 を優先する時代へと移行しました。
技術的な難易度と地政学的な制約が交差する中で、
複数地域に安定した製造ネットワークを構築できる企業こそが、次世代AIインフラの中心的プレイヤーとなります。
2030年のAI半導体地図 ― すべての密度が交差する未来
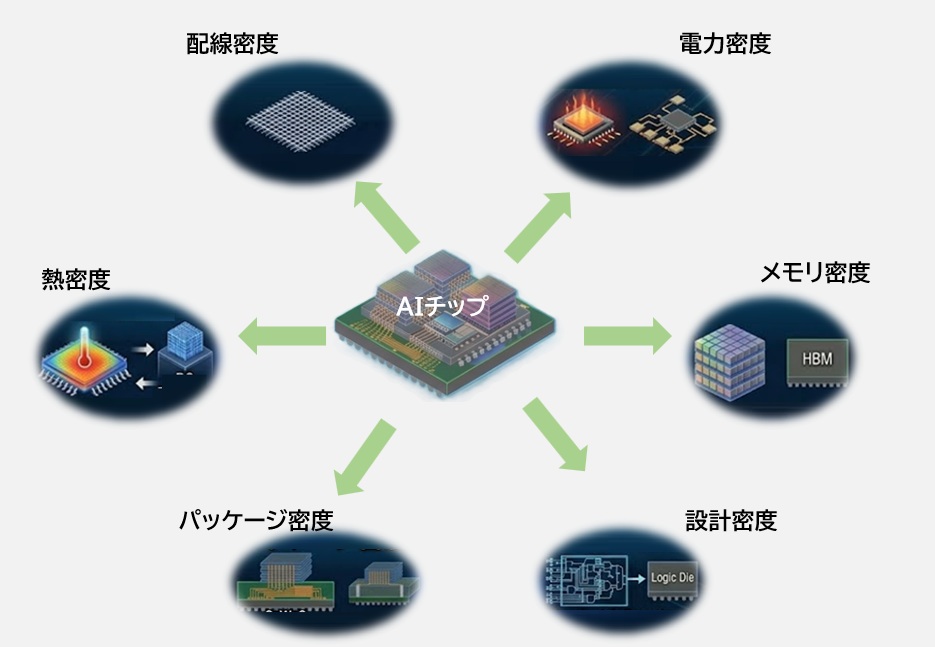
2030年のAI半導体は、これまで個別に語られてきた技術課題が限界に達し、それらが複雑に絡み合う「統合構造」へと収束します。
もはや単一の技術革新だけで性能を押し上げる時代ではなく、複数の“密度”をどうバランスよく最適化するか が設計の中心になります。
すべての密度が収束する構造体
2030年のAI半導体は、次のような技術の“交差点”として姿を現します。
- 微細化 → 配線・電源構造の最適化へ
線幅の縮小だけでは性能が伸びず、BSPDNなどによる配線密度の最適化が基盤技術となります。 - 電力 → パワー・アーキテクチャへ
1,000W級の熱を前提に、電力密度を抑えた設計と液冷などのインフラが不可欠。 - メモリ → 階層型ストレージへ
HBM単体の限界を認め、CXLやNANDを組み合わせたヘテロなメモリ階層が標準化。 - 単一チップ → システム・パッケージへ
CoWoSや3D積層により、パッケージ全体が“1つの巨大コンピューター”として機能します。 - 人間中心 → AIによる自律設計へ
設計複雑度の爆発に対し、AI支援EDAが事実上の必須ツールとなります。 - 集中製造 → レジリエンス重視の多極化へ
技術・コスト・地政学リスクを分散した多地域製造ネットワークが求められます。
これらの要素は互いに独立しておらず、密度の最適化という共通軸で結びついています。
「密度の最適化」を制するプレイヤー
2030年のAI半導体地図で主導権を握るのは、TSMC・Samsung・Intelといった大手ですが、勝敗を分けるのは単なる技術力ではありません。
重要なのは、
デバイス、パッケージ、ソフトウェア、電力、冷却、サプライチェーンを“1つのシステム”として最適化できるか
という総合力です。
特定のプロセス技術に優れているだけでは不十分で、
複数の密度を同時に制御し、全体として最大性能を引き出せる企業こそが、2030年の中心に立つことになります。
まとめ ― 2030年のAI半導体は“構造を読める者”が勝つ
本連載では、「密度」という多層的な視点から2030年のAI半導体地図を読み解いてきました。
かつて半導体産業を支配していた「微細化=性能向上」というシンプルな方程式は、物理的・電気的な限界によって終わりを迎えつつあります。
構造戦争の時代への突入
2030年のAI半導体における競争の本質は、単一のデバイス技術ではありません。
複数の“密度”が複雑に絡み合う 「構造戦争」 へと完全に移行しています。
- 垂直方向の進化
トランジスタの微細化だけでなく、BSPDNによる電源供給構造の刷新、3D積層パッケージングの普及など、構造そのものを変えるアプローチが中心に。 - システム全体の最適化
電力・熱・メモリ帯域といったボトルネックを、HBM+CXLの階層化など“システムレベル”で解消する設計思想が不可欠。 - 設計と製造の再定義
爆発する設計複雑度をAIで制御し、地政学リスクを織り込んだ多極的な供給網を構築することが、企業の競争力を左右する。
もはや「どのプロセスノードが最先端か」だけでは勝敗は決まりません。
“構造を読める者”が勝つ
これからのAIチップを理解し、その未来を見通すには、
配線・電力・熱・メモリ・パッケージ・設計・地政学
といった複数のレイヤーを同時に俯瞰する視点が欠かせません。
スペック表の数字だけを追っても、本質にはたどり着けません。
重要なのは、それらの要素がどのように結びつき、
「密度」という概念のもとでどのように最適化されているか を読み解くことです。
2030年、この多層構造を最も緻密に設計し、全体最適を実現できる企業こそが、次世代コンピューティングの覇権を握ることになるでしょう。
本シリーズが、AI半導体の深層で進む構造変化を捉え、技術と産業の大きな流れを先読みする一助となれば幸いです。

