

はじめに
生成AIの急拡大により、AIインフラの主役は“演算”から“メモリ”へと移りつつあります。
モデル規模が数兆パラメータへ拡大する中、性能を決めるのはGPUの演算能力ではなく、高速かつ大量のデータをメモリから供給できるかに変わりました。
その中心にあるHBMはAIを支えてきましたが、容量不足・高コスト・電力負荷という限界が明確になっています。

こうした課題を背景に、HBMとSSDの間を埋める新しい“中間メモリ層”としてHBF(High Bandwidth Flash)が注目され、さらに外部メモリを内部メモリのように扱えるCXL(Compute Express Link)が普及し始めています。
これら技術の登場により、AIデータセンターはHBM単独の構造から、HBM・HBF・SSDが階層化されたメモリネットワーク型アーキテクチャへ移行する可能性が高まっています。
この新しい階層をめぐり、SK hynix・Samsung・NVIDIAを中心に覇権争いが本格化しています。
本コラムでは、HBMの限界、HBFとCXLの本質、主要企業の戦略、そして2035年のAIデータセンターの姿を解説します。
HBMの限界が表面化
HBMは、GPUと同一パッケージに積層され、従来DRAMでは到達できなかった帯域幅を実現したことで、生成AIの学習性能を大きく押し上げました。
AI需要の急拡大により、HBMはその限界が表面化しています。
現在のAIデータセンターが抱える多くの課題は、このHBMへの過度な依存が要因の一つです。
容量の限界 (急速に大型化するモデルに対応できない)
HBMは高速である一方、構造的に容量拡張が難しいという致命的な制約があります。
- 積層構造(3D TSV)のため、積めるダイ数に制約
- 最新GPUでも容量は数十GB
- 数千億〜数兆パラメータのモデルには明らかに容量が不足
特に推論ではモデル全体を高速に参照する必要があるため、HBM容量不足は性能低下に直結します。
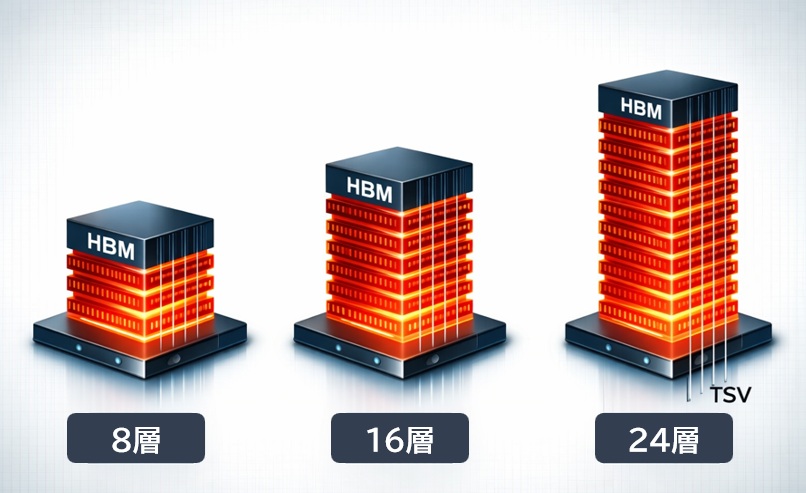
(参考)HBM積層数の現状と将来
| 世代 | 積層数 | 状況 |
| HBM2E / HBM3 / HBM3E | 8層(8‑Hi) | 量産の実質上限 |
| HBM4(初期) | 12〜16層 | 開発・試作段階 |
| HBM4/5(将来) | 24層(24‑Hi) | 研究段階・2030年以降 |
コストの高騰
HBMは製造難易度が高く、歩留まりも安定しにくいため、DRAMの数倍〜十倍以上の価格帯です。
HBMコストが高い理由は、
- TSVによる複雑な積層工程
- 高熱密度に対応する先端パッケージングが必要
- 供給能力(量)が限られ、需要の急増に対応が困難
- SK hynixの高い価格決定力
結果として、
「HBM価格=GPU価格の高騰」
という構造が生まれています。
GPU原価に占めるHBM比率は急増し、AIインフラの投資効率を押し下げています。
電力・冷却のキャパシティ限界
HBMは高速動作のため電力消費が大きく、発熱も増加します。
- GPU1台あたりの消費電力が増加
- ラック密度が制限される
- 冷却設備の増強が必要
- データセンターの電力契約が逼迫
欧米・アジアの主要都市では電力供給が限界に近づき、「電力不足でAIデータセンターが建てられない」という状況も現れています。
HBFとCXLへの期待
こうした背景から、HBMを補完し、これらの制約を緩和する新しいメモリ階層が求められています。
その有力候補が、HBMとSSDの間を埋める HBFと、外部メモリを内部メモリ化する CXLです。
HBFとは何か
HBFは単なる高速SSDではなく、NANDフラッシュを高速化し、HBMとSSDの間を埋める新しい中間メモリ層として設計されています。
HBFの技術的本質

HBFは、NANDを大規模並列化し、従来SSDより低レイテンシ・高帯域で動作させることで、CPU/GPUから直接アクセス可能な“メモリ的フラッシュ”を実現します。
- SSDより圧倒的に高速
- HBMより遅いが大容量
- CXL経由でメモリ空間として扱える
- 数百GB〜数TBの容量を確保可能
HBMの「速いが小さい」と、SSDの「大きいが遅い」の間を埋めるのがHBFの役割です。
HBMとの違い (速度・容量・コストのバランスが異なる)
HBMは最速だが容量が小さく、HBFは十分な速度と大容量を両立します。
| 項目 | HBM | HBF |
| 速度 | 超高速(ナノ秒級) | 中速(マイクロ秒級) |
| 容量 | 数十GB | 数百GB〜数TB |
| コスト | 非常に高い | 低い(NANDベース) |
| 接続 | GPUパッケージ内 | CXL経由で外部接続 |
| 役割 | 最上位キャッシュ | 中間メモリ層 |
なぜ“中間メモリ層(HBF)”が必要なのか
AI推論では、HBMほどの速度が不要なデータが多く、SSDでは遅すぎるという“中間帯域”が存在します。
HBFはこの領域に最適化されており、次の効果が期待できます。
- 推論コストの大幅削減
- 電力効率の改善
- モデルロード時間の短縮
- HBM搭載量の最適化
特に推論では、モデル全体を保持できる大容量メモリが重要であり、HBFはその現実的な解決策となります。
HBFの限界と前提条件
HBFは万能ではなく、いくつかの制約があります。
- レイテンシはHBMより大きい
※レイテンシ(latency):データを要求してから実際に届くまでの遅延時間のこと - 書き換え耐久性に限界
※書き換え耐久性(write endurance):フラッシュメモリが「書き込み・消去」を何回繰り返せるかを示す寿命指標のこと - コントローラ処理が必要
そのため、「GPUが今まさに使う、最もアクセス頻度の高いデータホットデータをHBM、その他をHBF」 という階層化が前提となります。
CXLが不可欠な理由
HBFはCXLがあって初めて“メモリ”として機能します。
- PCIeではレイテンシが大きすぎる
※PCIe(ピーシーアイ・イー):コンピュータ内部でCPUと周辺デバイスを高速に接続するための標準インターフェースです。 - 従来SSDのようにストレージ扱いになる
※ストレージ :SSDやHDDのようにデータを長期間保存するための不揮発性領域のこと - CPU/GPUから直接アクセスできない
CXLは外部メモリを内部メモリのように扱える規格であり、HBFを中間メモリ層として成立させる鍵です。
■メモリとストレージの違い
| 種類 | 役割 | 特徴 |
| メモリ(HBM/DRAM/HBF) | 計算中のデータを一時的に保持 | 高速・揮発性 |
| ストレージ(SSD/HDD) | データを長期間保存 | 低速・不揮発性 |
■メモリ階層ごとのレイテンシの違い
| 階層 | レイテンシの目安 | 特徴 |
| HBM | 数百ナノ秒 | GPUに最も近く、超高速 |
| DRAM | 数十〜百ナノ秒 | CPU/GPUの主記憶 |
| HBF(CXLメモリ) | 数百ナノ秒〜数マイクロ秒 | DRAMより遅いが大容量 |
| SSD(NVMe) | 数十〜百マイクロ秒 | ストレージとしては高速 |
| HDD | 数ミリ秒 | 機械的動作で最も遅い |
HBFがもたらす構造変化
HBFの登場により、AIデータセンターのメモリ階層は次のように再構築されます。
- HBM:最上位キャッシュ
- HBF:中間メモリ層(推論モデル保持)
- SSD:アーカイブ層
この三層構造により、AIインフラは性能・コスト・電力のバランスを最適化できます。
CXLがメモリをネットワーク化にする
HBFが“中間メモリ層”として機能するためには、CXL が不可欠です。
CXLの本質 (外部メモリを“メインメモリ化”する技術)

CXLはPCIeをベースにしつつ、従来のインターフェースでは実現できなかった機能を備えています。
- 外部メモリをCPU/GPUから直接アクセス可能に
- キャッシュ整合性を維持
- PCIeより低レイテンシ
- メモリ空間を拡張・共有できる
これにより、サーバー単位で固定されていたメモリが、ラック全体で共有される“メモリネットワーク”へと進化します。
CXLがもたらす3つの構造変化
1. メモリプール化(共有)
複数サーバーが1つの大容量メモリ空間を共有でき、遊休領域を大幅に削減できます。
2. メモリ階層の拡張
CXLメモリを追加するだけで、TB級のメモリ空間を構築可能。
HBMの容量不足を補完します。
3. モデルロードの高速化
モデルを共有メモリに置くことで、サーバー間のデータ移動が減り、推論の立ち上がりが高速化します。
HBFがCXLなしでは成立しない理由
HBFはNANDベースであるため、HBMほどの低レイテンシはありません。
そのため、CXLによる高速・低遅延アクセスが前提条件になります。
- PCIe接続ではレイテンシが大きすぎる
- 従来SSDのように“ストレージ扱い”になってしまう
- CPU/GPUから直接メモリとして扱えない
CXLがあることで、HBFは初めて「中間メモリ層」として機能します。
CXLがAIインフラのボトルネックを解消する
HBM依存の三重制約(容量・コスト・電力)は、CXLによるメモリネットワーク化で大きく緩和されます。
- HBMの容量不足 → CXLメモリで補完
- HBMの高コスト → HBFで大容量を安価に確保
- 電力制約 → HBM搭載量を最適化し負荷を軽減
CXLは、AIインフラを“HBM中心”から“メモリ階層中心”へと移行させる基盤技術です。
主な企業別戦略 (誰が“次のメモリ階層”を制するか)
HBMで莫大な利益を上げてきたSK hynix、巻き返しを狙うSamsung、AIインフラの中心に立つNVIDIA、そしてNANDメーカーやCPUメーカーまで、各社が“次のメモリ階層”をめぐって動き始めています。
SK hynix :HBM覇者としての優位性
SK hynixはHBM市場で圧倒的シェアを持ち、NVIDIAの主要サプライヤーとしてAIインフラの中心にいます。
HBFに最も積極的と見られてます。
<狙い>
- HBM覇権をHBFにも拡張
- NAND事業の収益改善
- NVIDIAとの関係強化
<強み>
- HBMの技術力・量産力
- NAND製造力
- CXLメモリモジュール開発
<リスク>
- HBF普及でHBM利益率が低下
- 供給能力の拡大が追いつかない可能性
Samsung :垂直統合を武器に“逆転”を狙う
HBMではSK hynixに遅れていますが、HBFとCXLの領域では巻き返しの余地があります。
<狙い>
- HBMの遅れをHBFで挽回
- NAND巨大投資の出口としてHBFを活用
- 自社サーバーソリューションとの統合
<強み>
- DRAM・NAND・ロジック・パッケージングの垂直統合
- 世界最大のNAND製造能力
<リスク>
- HBMの遅れがブランドに影響
- HBF市場が立ち上がらない場合の投資回収リスク
Samsungは“HBMで負けてもHBF×CXLで勝つ”戦略を描いるようです。
SanDisk(Western Digital) :NAND市場の“復活”をかけた挑戦
NANDメーカーにとってHBFは、価格競争から脱却するための数少ないチャンスです。
<狙い>
- NANDの高付加価値化
- HBFを新たな収益源に
- OCPで標準化を主導
※OCP(Open Compute Project) :Metaが中心となって始まったオープンなデータセンター技術の標準化団体です。Meta(Facebook)/Google/Microsoft/Amazon(AWS)/Intel/AMD/NVIDIA/SK hynix/Samsungなど、世界の主要クラウド・半導体企業が参加しています。目的は、データセンターのサーバー・ストレージ・ネットワーク・電源・メモリなどの仕様を共通化し、効率化すること。
<強み>
- NAND技術の蓄積
- データセンター向けSSDの顧客基盤
<リスク>
- DRAMを持たず、HBMとの統合戦略が弱い
- HBF市場立ち上がりの遅れ
HBFはSanDiskにとって“復活の切り札”となり得るかもしれません。
NVIDIA :HBF採用がGPU戦略を変える
NVIDIAはAIインフラの中心であり、HBM依存度が極めて高い企業です。
HBF採用の判断は市場全体に大きな影響を与えるでしょう。
<狙い>
- HBM依存を緩和し設計自由度を確保
- 推論コストを下げAI普及を加速
- CXLでGPUクラスタの効率向上
<HBF採用の効果>
- HBM搭載量の最適化
- 電力効率改善
- 推論サーバーのコスト低下
<リスク>
- ソフトウェア最適化の負荷増大
- サプライチェーンの再構築が必要
NVIDIAが採用すると、HBF市場は一気に立ち上がる可能性があります。
Intel / AMD :CXL普及の“鍵”を握るCPUメーカー
HBFはCXLが前提であり、その普及を決めるのはCPUメーカーです。
<狙い>
- CPU中心のメモリネットワーク構想を推進
- CXL対応サーバーで新しい価値を創出
<強み>
- CXL規格策定の中心
- サーバーCPU市場での存在感
<リスク>
- GPU中心のAIインフラが続くと普及が遅れる
■企業戦略の比較
| 企業 | 強み | 狙い | リスク |
| SK hynix | HBM覇権 | HBF標準化 | HBM利益率低下 |
| Samsung | 垂直統合 | HBFで逆転 | 投資回収 |
| SanDisk | NAND技術 | HBFで高付加価値化 | 市場立ち上がり |
| NVIDIA | AIインフラ中心 | HBM依存緩和 | ソフト最適化負荷 |
| Intel/AMD | CXL主導 | メモリネットワーク化 | 普及速度 |
ハイパースケーラーの本音
AIメモリ覇権争いの最終的な勝者を決めるのは、SK hynixでもSamsungでもNVIDIAでもありません。
AWS・Google・Microsoft・Meta といったハイパースケーラーです。
彼らは世界のAIインフラ投資の大半を担い、GPU・メモリ・ストレージの採用方針を決めることで、サプライチェーン全体の方向性を左右します。
ハイパースケーラーが重視する3つの指標
1. 1ドルあたり性能
推論コストはサービス全体の利益に直結します。
HBFはHBMより安価で大容量のため、推論コストを大幅に下げられる可能性があります。
2. 1ワットあたり性能
電力はAIインフラ最大の制約です。
HBM中心の構造は電力負荷が大きく、HBF+CXLの導入は電力効率改善に寄与します。
3. ラック密度
HBMは発熱が大きく、搭載台数が制限されます。
HBFを併用することで、HBM搭載量を最適化し、ラック密度を高められます。
ハイパースケーラー別の視点
- AWS:Inferentia/Trainiumとの組み合わせでHBFに強い関心
※Inferentia(インフェレンシア)とTrainium(トレイニアム):AWS(Amazon Web Services)が自社で設計したAI専用チップ - Google:TPUのメモリ階層最適化が急務
- Microsoft :OpenAI連携で推論需要が急増
- Meta :Llama推論の膨大な回数によりコスト削減が最優先
※Llama推論:Metaが公開している大規模言語モデル「Llama(LLaMA)」を使って、テキスト生成・要約・翻訳などの処理を実行すること
いずれも共通しているのは、推論コストと電力効率の改善が最重要という点です。
採用すれば市場は一気に立ち上がる
ハイパースケーラーがHBFを採用すれば、HBF市場は一気に立ち上がり、NANDメーカーの収益構造が劇的に変わります。
逆に採用されなければ、技術が優れていても普及しません。
ハイパースケーラーの決定は、
- HBMの価格構造
- HBFの普及速度
- CXLサーバーの導入ペース
- GPUアーキテクチャの方向性
すべてに影響を与えます。
ハイパースケーラーが求める“次のメモリ階層”
ハイパースケーラーが求めているのは、HBMの性能を維持しつつ、コストと電力を抑えられるメモリ階層 です。
その答えとして、
- HBM(最上位)
- HBF(中間層)
- SSD(下位層)
- CXL(接続基盤)
という構造が最も現実的な選択肢になりつつあります。
2035年のAIデータセンター
2035年のAIデータセンターは、現在とはまったく異なる姿になっている可能性があります。
最大の変化は、GPU中心の設計から “メモリ中心アーキテクチャ” への移行です。
HBMの限界を補うために、HBFとCXLを組み合わせた新しいメモリ階層が標準化しつつあります。
メモリ階層は「3層構造」が標準

AIインフラは、性能・コスト・電力のバランスを取るために、次の三層構造へ移行します。
- HBM(最上位):超高速だが小容量。ホットデータを保持。
- HBF(中間層):中速・大容量。推論モデルの常駐先として最適。
- SSD(下位層):低速・超大容量。アーカイブ用途。
この構造により、HBMの容量不足を補いながら、推論コストと電力負荷を大幅に抑えられます。
■2035年のメモリ階層
| 階層 | 技術 | 容量 | 速度 | 主な役割 |
| 最上位 | HBM | 数十GB | 超高速 | キャッシュ・ホットデータ |
| 中間 | HBF | 数百GB〜数TB | 中速 | 推論用モデル保持 |
| 下位 | SSD | 数TB〜PB | 低速 | アーカイブ・低頻度データ |
この3層構造により、AIデータセンターは性能・コスト・電力のバランスを最適化できます。
メモリネットワーク化が進む
CXL の普及により、メモリはサーバー単位ではなく ラック全体で共有 されるようになります。
- モデルロード時間が大幅に短縮
- メモリの未使用領域がほぼなくなる
- GPUがメモリに合わせて動く時代の設計になる
- サーバー間のデータ移動が減り、推論効率が向上
これにより、従来の「GPUにどれだけHBMを積むか」という発想から、
「ラック全体でどれだけメモリを確保し、どう共有するか」
へと設計思想が変わります。
推論コストは劇的に低下する
HBFとCXLの導入により、推論コストは大きく改善します。
- HBM搭載量を最適化し、GPU価格を抑制
- 電力効率の向上でラック密度が増加
- モデルロードの高速化でサーバー稼働率が上昇
特に推論は学習よりも回数が圧倒的に多いため、コスト削減効果は非常に大きく、AIサービスの普及をさらに加速させます。
AIデータセンターの設計思想が変わる
2035年のデータセンターは、次のような特徴を持つと考えられます。
- メモリ階層が主役
- GPUはメモリネットワークの一部として動作
- HBMは最上位キャッシュとして位置づけられる
- HBFが推論の大容量メモリとして中心的役割を担う
- CXLがメモリ共有の基盤となる
つまり、AIインフラの競争軸は「演算性能」から「メモリ階層の設計力」へと完全に移行します。
メモリ中心アーキテクチャがもたらす産業構造の変化
- HBM単独の価値は相対的に低下
- NANDメーカーがAIインフラの中心に躍り出る可能性
- CPUメーカー(Intel/AMD)がCXLで存在感を取り戻す
- GPUメーカーはメモリ階層との統合力が競争力に
AIインフラの主導権は、単一企業ではなく メモリ・GPU・CPU・クラウドの連携 によって決まる時代になります。
まとめ
AIインフラの中心は、いまやGPUの演算性能ではなく“メモリ”へと移りつつあります。
モデル巨大化と推論需要の増大により、HBMだけでは容量・コスト・電力の限界が明確になり、HBFとCXLを組み合わせた新しいメモリ階層が不可欠になりました。
2035年のAIデータセンターでは、HBM・HBF・SSDが階層化され、CXLによってラック全体でメモリを共有する“メモリ中心アーキテクチャ”が主流になります。
この未来を主導するのは、HBM・HBF・CXLを高いレベルで統合し、ハイパースケーラーの要求に応えられる企業です。
AIメモリ戦争はまだ始まったばかりであり、2035年に向けて産業構造は大きく変わっていくでしょう。

