

はじめに

生成AIの普及により、AI向けGPUの需要はかつてないスピードで拡大しています。
その中心にあるのが、GPUと密接に連携する超高速メモリHBMです。
HBMは複数のDRAMチップを縦に積み上げ、TSVで接続することで、従来DRAMを大きく上回る帯域を実現します。
しかし現在、HBMは世界的に深刻な供給不足に陥っています。
一般的には「生産が追いつかない」と認識されていますが、実際には製造面の限界と性能面の限界という二つの構造的課題が背景にあります。
本コラムでは、この不足がなぜ起きているのかを技術と市場の両面から解説し、さらに各社がどのようにこの限界を突破しようとしているのかを整理します。
本コラムは連載の第3回目です。
・第1回:AIチップの2nm競争は“配線密度”で決まる HBM・RDL・BSPDNが変える半導体構造
・第2回:【2026年最新】AI-DCは“電力密度限界”で崩壊かー電力・消費電力・電源設計の本質
・第3回:HBMはなぜ“足りない”のか ― 需給逼迫の裏にある「製造+性能」限界の宿命(本稿)
・第4回:CoWoSとHBM不足の真因:TSMC・Intel・Samsungの覇権争いと2035年AIパッケージロードマップ
・第5回:2nm設計は「EDA × アーキ × DTCO × パッケージ × 検証」の総合戦争
・第6回:2030年のAI半導体地図 ー 2nm・HBM・パッケージ・電力のすべてが交差する未来
HBMが不足する理由 ― 製造キャパシティ・歩留まりの壁
積層構造が生む高難度の製造工程

HBMは複数のDRAMチップを縦に積み上げ、TSVで接続する特殊構造です。
このTSV形成は極めて難しく、わずかな位置ずれや加工誤差が接続不良につながります。
また、積層数が増えるほど加工精度の要求が高まり、積層後の熱ストレスによってチップが変形するリスクが高まります。
そのために、HBMは歩留まりが低く、生産量が伸びにくい課題を抱えています。
| 工程 | 課題 |
| TSV形成 | 微小な位置ずれが接続不良に直結 |
| 積層工程 | 積層数増加で精度要求が急上昇 |
| 熱ストレス | 積層後の変形リスク |
DRAM微細化の限界が積層依存を加速
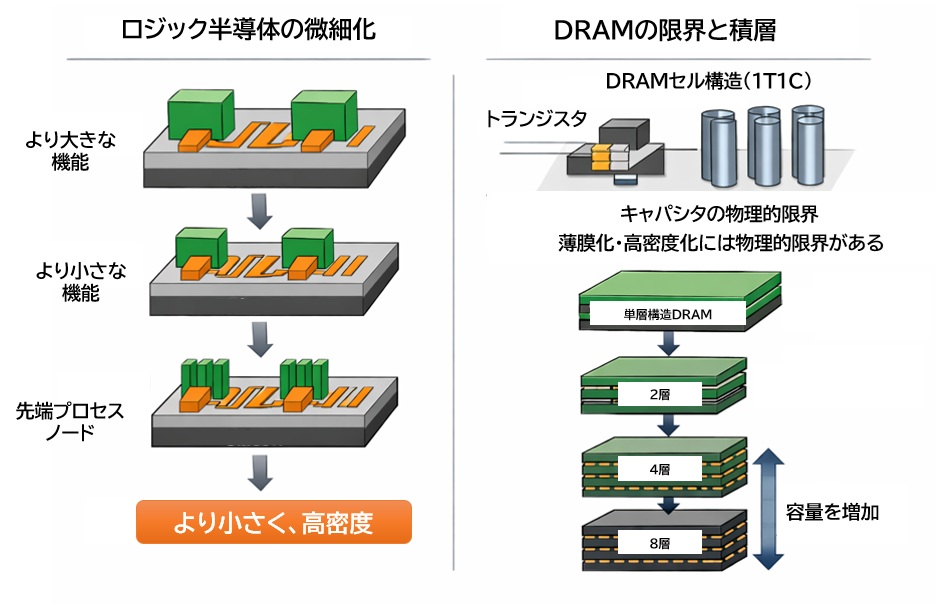
ロジック半導体が2nm世代へ向かう一方、DRAMは構造上の理由から微細化が難しくなっています。
DRAMセルは電荷をためるキャパシタを必要とし、一定以上は小さくできません。
容量を増やすには積層に頼らざるを得ず、結果として歩留まり悪化が避けられません。
ロジック半導体 vs DRAM の微細化比較
| 項目 | ロジック半導体 | DRAM |
| 微細化 | 2nm世代へ進展 | キャパシタ構造の限界で困難 |
| 容量増加手段 | 微細化で対応 | 積層依存 |
| 課題 | 電力・リーク | 歩留まり悪化 |
需要と供給のギャップは年々拡大
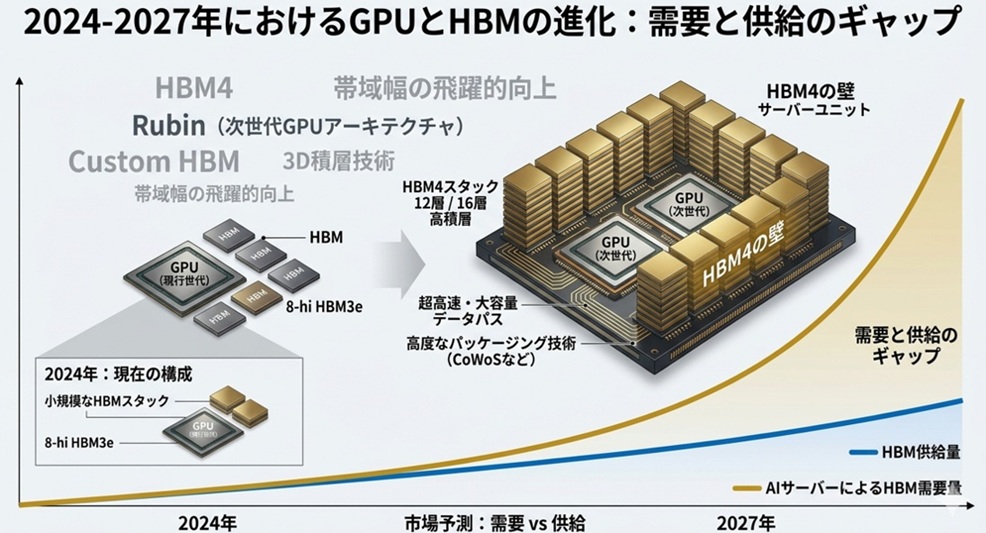
AI向けGPUの需要増により、HBM需要は2024〜2025年にかけて急拡大しました。
(下表の2026~2027年は、予測の参考値です。)
| 年度 | 需要量 (スタック換算) | 供給量 | 不足率 |
| 2024 | 約3.5〜4億 | 約2.3〜2.6億 | 約30〜40%不足 |
| 2025 | 約5億超 | 約3.5〜4億 | 約20〜30%不足 |
| 2026 (予想) | 約7.5〜8.5億 | 約6.0〜6.8億 | 約20%不足 |
| 2027 (予想) | 約11.5億超 | 約10.0億前後 | 約10〜15%不足 |
GPU1台あたりのHBM搭載量も増加しており、H100の80GBからB100では192GBへと拡大しています。
GPU1台あたりのHBM使用量が増えたことで、供給不足はさらに深刻化しています。
| GPU世代 | HBM容量 |
| H100 | 80GB |
| B100 | 192GB |
性能面の限界 ― 熱と電力がHBMの成長を止め始めた
| 限界要因 | 具体的な問題 |
| 熱 | 中央部が過熱しやすい |
| 実効性能 | ECC増加・帯域低下 |
| 電力 | スタック20W超 |
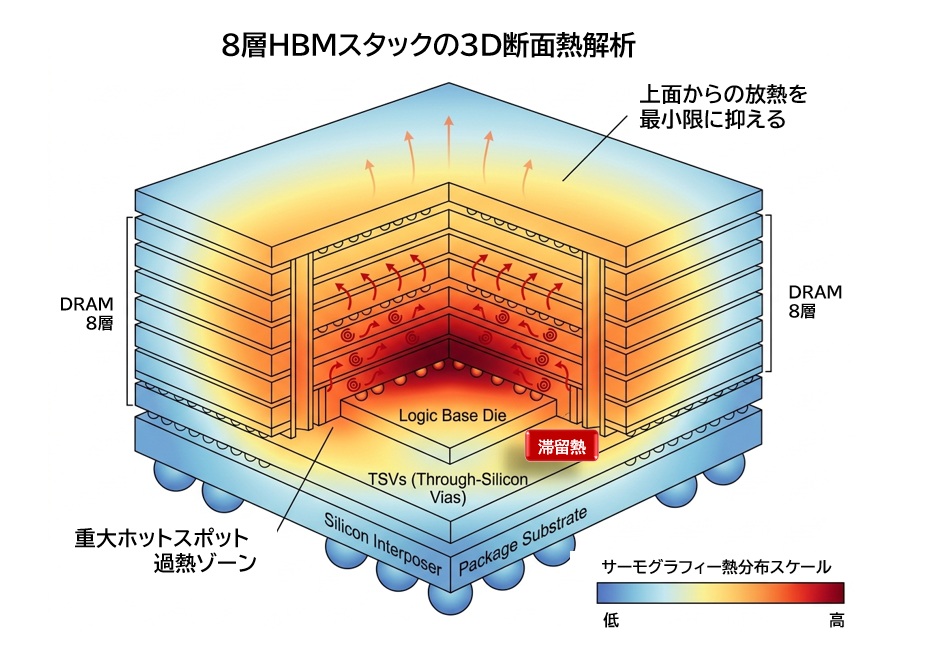
積層構造ゆえの“中央が熱くなる”問題
HBMは積層構造のため、中央部に熱がこもりやすく、温度上昇に弱く、メモリにとって大きな課題となります。
温度が上がるとデータ保持が不安定になり、リフレッシュ回数の増加やエラー率の上昇を招きます。
※リフレッシュ回数とは:DRAMセルに蓄えたデータが自然に消えてしまうため、定期的に書き直す動作のこと
結果として、動作周波数を下げざるを得ないケースも増えています。
実効性能の低下が顕在化
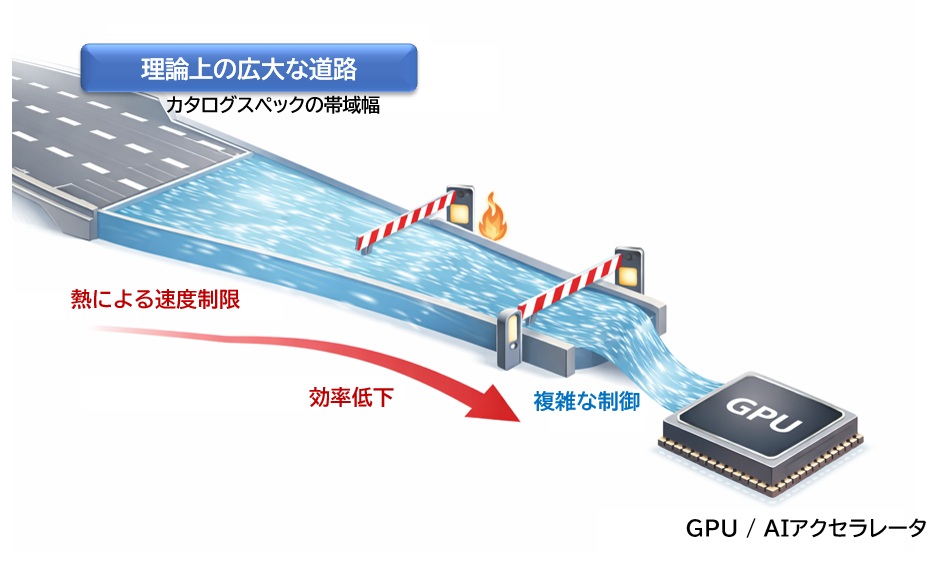
HBM3Eは理論帯域が1TB/sを超える製品もありますが、実際のシステムでは熱の影響により最大性能を維持できないことが増えています。
ECCの発生やリフレッシュ増加により、実効帯域が理論値の70〜80%にとどまるケースもあります。
※ ECC (Error Correcting Code):メモリ内で発生したビットエラーを自動で検出・修正する仕組み
さらに、GPT-4級モデルではGPUが計算よりもメモリ待ちで時間を浪費する状況が増えており、実効性能が理論値の50〜60%に低下することもあります。
電力増大と冷却コストの上昇
HBM3Eは高帯域を実現するために大量のI/Oを同時に動作させる必要があり、スタックあたり20Wを超える製品もあります。
GPU全体では700W級の冷却が必要となり、データセンターの運用コストを押し上げています。
各社の戦略・技術ロードマップ・実現時期
| 企業 | 製造限界への対策 | 性能限界への対策 | 実現時期 |
| SK hynix | TSV自動化・薄型ウェハ | 熱拡散構造・HBM5再設計 | 2026〜2029 |
| Samsung | モノリシックTSV | X-Cube・内蔵ヒートスプレッダ | 2026〜2028 |
| Micron | 低ダメージTSV | 高熱伝導フィルム | 2026〜2029 |
SK hynix ― 品質主導の戦略
■ 製造限界への対応
- 2025〜2027年にかけて、韓国・中国・米国のHBMラインを段階的に増強
- TSV形成工程の自動化率を引き上げ、歩留まり改善を継続
- 2026年以降は「薄型ウェハ+低ストレス積層」技術を導入し、積層時の変形を抑制
■ 性能限界への対応
- HBM4では「高熱伝導材料の採用」「積層間の熱拡散構造」を導入
- GPU側との協調設計をTSMCと共同で進め、熱源配置を最適化
- 2027年以降は“HBM5”に向けて、積層構造そのものを再設計する計画
■ 実現時期
- HBM4:2026年量産
- HBM4E:2027年
- HBM5:2028〜2029年に試作開始と予測
Samsung ―パッケージング主導の戦略
■ 製造限界への対応
- 2025〜2026年にかけて、TSV工程の歩留まり改善に集中
- 自社ファウンドリとの連携を強化し、HBMとロジックの協調設計を推進
- 2026年には「モノリシックTSV」技術を導入し、接続不良を大幅に削減する計画
■ 性能限界への対応
- 3Dパッケージング技術「X-Cube」をHBM4に適用
- 熱拡散層をHBM内部に組み込む“内蔵型ヒートスプレッダ”を開発
- 2027年以降は、HBMとロジックを同一基板上で統合する“HBM-PIM”を本格展開
■ 実現時期
- HBM4:2026年初頭に量産開始
- HBM-PIM:2027〜2028年に商用化
Micron ― 歩留まり主導の戦略
■ 製造限界への対応
- 日本(広島)と米国(アイダホ)のHBMラインを増強
- TSV形成工程を独自の「低ダメージ加工」に置き換え、歩留まりを大幅改善
- 2025年時点でHBM3Eの歩留まりは業界トップ級との評価もある
■ 性能限界への対応
- HBM4では「低電圧I/O」「高効率リフレッシュ制御」を導入
- 熱問題に対しては、積層間に“高熱伝導フィルム”を挿入する独自技術を採用
- 2028年以降は、HBMをチップレット化し、GPUと同一パッケージ内で柔軟に配置できる構造を目指す
■ 実現時期
- HBM4:2026年後半
- HBM4E:2027年
- チップレットHBM:2028〜2029年
TSMC・Intel・AMD・NVIDIA ― パッケージング側の戦略
HBMの限界はメモリ単体では解決できず、GPU側のアーキテクチャ改革が不可欠です。
| 企業 | 技術 | 目的 |
| TSMC | CoWoS拡張 | HBMスタック増加・熱拡散 |
| Intel | EMIB+Foveros | 接続距離短縮・3D統合 |
| NVIDIA | オンパッケージキャッシュ | HBM依存低減 |
■ TSMC(CoWoSの拡張)
- CoWoSの基板サイズを2025〜2027年にかけて2倍へ拡張
- HBM 8スタック→12スタック→16スタックへ対応
- 熱拡散層を基板側に追加し、HBMの温度上昇を抑制
■ Intel(EMIB+Foveros)
- EMIBでHBMとの接続距離を短縮
- FoverosでロジックとHBMを3D統合
- 2027年以降は“HBM on CPU”構造を本格展開
■ NVIDIA(HBM依存の低減)
- 2026年以降のGPUでは、HBM帯域不足を補うための“オンパッケージキャッシュ”を増強
- HBM4世代では、GPU内部のデータフローを再設計し、メモリ待ち時間を削減
HBM4以降は新技術の未来

HBM4以降では、単にメモリ性能を上げるだけでは限界があります。
今後の鍵は、メモリとロジックの距離を縮め、システム全体として最適化することにあります。
- 2.5D/3Dパッケージング
- チップレット化
- UCIeによる標準化インターフェース
- 熱分散構造の革新
HBMはもはや“メモリ部品”ではなく、システムアーキテクチャを規定する中心技術へと進化しています。
まとめ
HBM不足は、単なる生産量の問題ではありません。
- 積層構造ゆえの製造難度
- 歩留まりの低さ
- 熱・電力による性能限界
- AI需要の爆発的増加
これらが同時進行した結果、HBMは慢性的な供給不足に陥っています。
しかし、主要メーカーはすでに次の一手を打ち始めています。
- SK hynix:品質主導でHBM4/5を牽引
- Samsung:パッケージング主導で巻き返し
- Micron:歩留まり主導で急成長
- TSMC・Intel・NVIDIA:パッケージングで限界突破
HBM4以降は、メモリとロジックの境界が曖昧になり、システム全体で性能を引き出す時代へと進みます。
HBMはAI時代の基盤を支える最重要技術として、今後も進化を続けていきます。

