

はじめに
生成AIの急速な普及により、世界ではこれまでにない規模でAI関連投資が進んでいます。
大規模言語モデル(LLM)の性能競争は勢いを増し、巨大IT企業やクラウド事業者、さらには各国政府までもがAIインフラの整備を加速させ、近年発表されるAIデータセンター計画は年々規模を拡大しており、数年前には想像できなかった投資額が動いています。
こうした状況の中で、多くの人々が注目するのはGPUです。
確かにGPUはAI時代の中心的存在であり、現在の生成AIはGPUなしには成立しません。
しかし、AI産業を支えているのはGPUだけではありません。
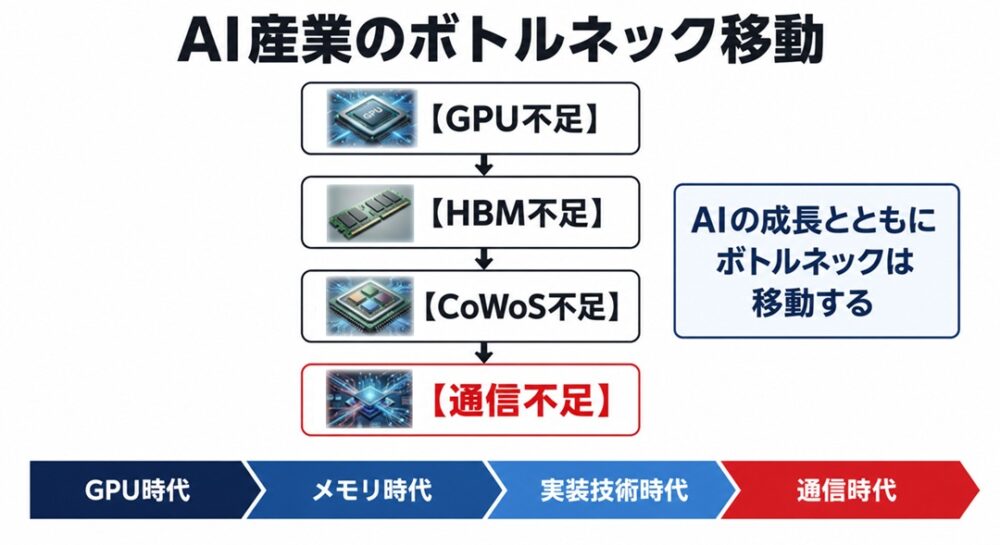
実際にここ数年の動向を振り返ると、AI産業のボトルネックは常に移動してきました。
ある時期にはGPUが不足し、その後はHBMが不足しました。
さらに先端パッケージ技術であるCoWoSも供給が追いつかない状況となりました。
そして現在、半導体業界や通信業界の関係者が次のボトルネックとして注目しているのが「通信」です。
AIモデルが巨大化するほど、GPU同士がやり取りするデータ量は急増します。
AIクラスタが数十万GPU規模へ拡大すると、もはや計算能力だけではなく、通信能力そのものが競争力を左右するようになります。
本稿では、なぜAI産業のボトルネックが通信へ移りつつあるのかを整理し、その解決策として期待される光電融合技術について考察します。
1.GPUの次に不足するもの
1-1.GPU不足から始まったAI競争
生成AIブームが本格化した2023年前後、世界中でGPU争奪戦が起きました。
GPUはもともと画像処理を高速化するために開発された半導体ですが、多数の演算を同時並列で処理できる特性がAIと極めて相性が良く、現在ではAI計算の中心的存在となっています。
大規模言語モデルの学習には膨大な計算能力が必要です。
数千億〜数兆パラメータ規模のモデルでは、一台のGPUで学習を完了することは不可能であり、数千台から数万台のGPUを接続し、一つの巨大な計算機として利用します。
生成AI市場の急拡大に伴い、
- クラウド事業者
- AIスタートアップ
- 通信事業者
- 研究機関
- 政府機関
が一斉にGPU調達へ動きました。
その結果、深刻なGPU不足が発生し、納期が1年以上に及ぶケースも珍しくありませんでした。
当時のAI競争は、まさにGPU確保競争そのものでした。
しかし、AIサーバーはGPUだけでは完成しません。
次に不足したのがHBMでした。
1-2.HBM不足はなぜ起きたのか
HBMは、高性能GPUと組み合わせて使用される高速メモリです。
AIでは計算能力だけでなく、データをどれだけ速く供給できるかが性能を左右します。
どれほど高性能なGPUでも、必要なデータを十分な速度で供給できなければ性能を発揮できません。
HBMは従来型メモリと比較して、
- 高帯域
- 低消費電力
- 高密度実装
という特徴を持ち、AI向けGPUの性能を引き出すために不可欠です。
しかしHBMは製造難易度が極めて高く、生産できる企業は限られています。
AI需要が急拡大すると、今度はHBM供給能力が不足しました。
GPUを製造できてもHBMがなければ出荷できない。
こうしてAI産業のボトルネックはGPUからHBMへ移動しました。

1-3.CoWoS不足はなぜ起きたのか
HBM不足の次に問題となったのがCoWoSです。
現在のAI向けGPUは、
- GPU本体
- HBM
- 接続基板
を一体化した高度な構造を採用しています。
この統合を支えているのが先端パッケージ技術です。
AI向け半導体では、チップ性能だけでなく、それらをどのように接続するかが重要になります。
GPUとHBMを高速接続するためには極めて高度な実装技術が必要であり、AI需要の拡大によってパッケージ工程が不足する事態が発生しました。
GPUはある、HBMもある、しかしパッケージ工程が足りない。
この現象は、サプライチェーン全体で最も不足している部分が生産量を決定することを示しています。
1-4.ボトルネックはなぜ移動するのか
ここまでを整理すると、
- 第一段階:GPU不足
- 第二段階:HBM不足
- 第三段階:CoWoS不足
という流れでボトルネックが移動してきました。
これは成長産業によく見られる現象です。
市場が急拡大すると、最も不足している部分が新たな制約になります。
そして現在、多くの企業が次のボトルネックとして警戒しているのが「通信」です。
なぜ通信なのか。
その答えはAIクラスタの巨大化にあります。
2.AIクラスタの巨大化が通信問題を生む
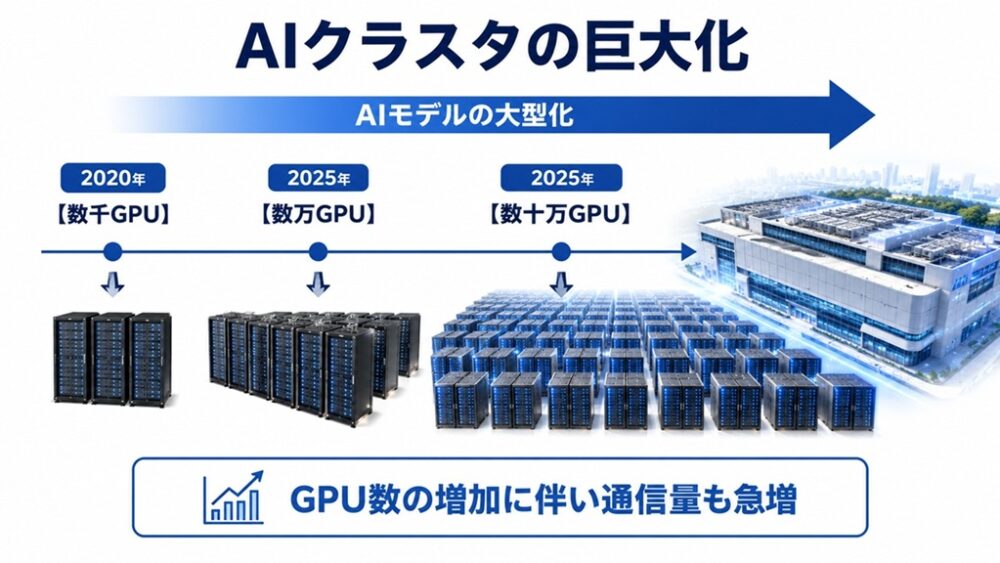
2-1.AIクラスタは数十万GPU時代へ
現在のAI開発では、単体GPUの性能向上だけではもはや十分ではありません。
重要なのは「何台のGPUを、どれだけ効率よく接続できるか」です。
大規模言語モデルの学習には膨大な計算が必要であり、AIクラスタは、
- 数千GPU
- 数万GPU
- そして数十万GPU
という方向へ急速にスケールしています。
すでに最先端のAI企業では数万GPU規模のシステムが稼働しており、2030年には10万GPUを超える構成が現実的な選択肢として検討されています。
しかしGPU数が増えるほど、新たな課題が浮上します。
それが通信です。
GPUを増やせば計算能力は向上しますが、同時にGPU間でやり取りされるデータ量も急増します。
結果として、計算能力よりも通信能力がシステム全体の性能を左右するようになります。
2-2.AI学習はGPU同士の共同作業
AI学習では、多数のGPUが一つのモデルを共同で学習します。
それぞれが独立して動いているわけではなく、あるGPUが計算した結果は他のGPUへ共有され、他のGPUの結果も受け取らなければ次の処理へ進めません。
つまりAI学習は、
- 計算
- 結果の共有
- 再計算
- 再共有
というサイクルを高速に繰り返す「共同作業」です。
この共有作業こそが通信であり、GPU数が増えるほど通信量は加速度的に増加します。
AIクラスタが巨大化すると、通信は単なる付随機能ではなく、システムの根幹を支える“性能そのもの”になります。
GPUが増えるほど計算能力は向上する一方で、通信が追いつかなければGPUは待機状態となり、全体の効率が大きく低下します。
この構造こそが、次世代AIインフラにおいて通信が最大の課題となる理由です。
3.通信量の爆発が始まる
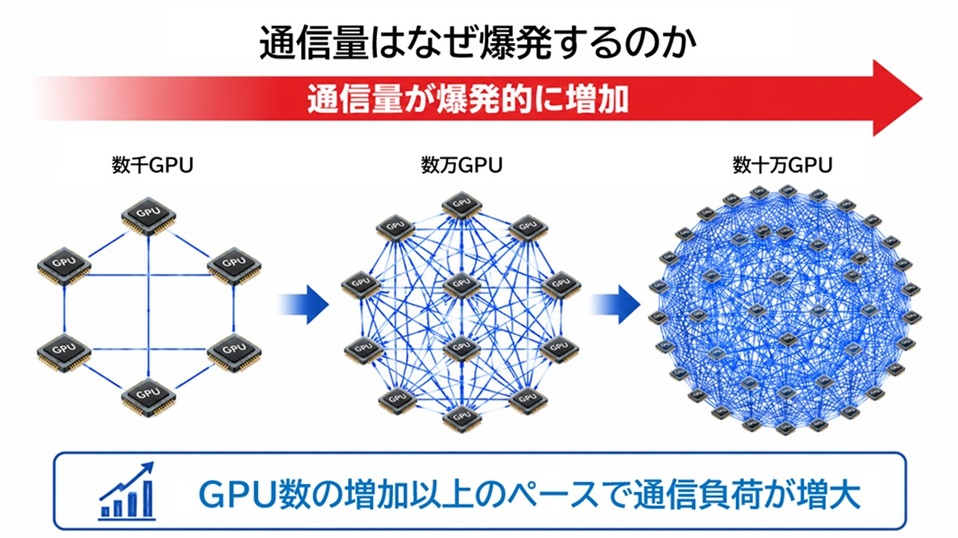
AIクラスタが巨大化すると、通信量は計算量以上の速度で増加します。
GPU数が10倍になったからといって通信量も10倍で済むわけではありません。
多数のGPUが相互に通信するため、通信負荷は非線形的に増大し、場合によっては20倍、30倍と跳ね上がることもあります。
大規模AI学習では、
- パラメータ更新情報
- 勾配情報
- 中間計算結果
などが常にGPU間でやり取りされています。
GPU数が増えるほど通信経路は指数的に増加し、その結果、通信量は爆発的に増加します。
これは単なる「データが増える」というレベルではなく、AIインフラ全体の設計思想を変えざるを得ないほどのインパクトを持っています。
3-1.計算待ちではなく通信待ちが発生する
従来のコンピューターでは、性能を決めるのは主に計算能力でした。
しかしAIクラスタでは異なる現象が起きます。
あるGPUが計算を終えても、他のGPUから結果が届かなければ次の処理へ進めません。
つまり、
- 計算能力は余っている
- しかし通信が終わらない
という状態が発生します。これが「通信待ち」です。
高価なGPUが待機状態になるため、システム全体の効率は大きく低下します。
GPUを増やしても性能が比例して伸びない「スケーリングの壁」が生まれるのは、この通信待ちが原因です。
AIクラスタが巨大化するほど、この問題は深刻になります。
3-2.AI競争は計算競争から通信競争へ
これまでのAI競争は、より高性能なGPUをどれだけ確保できるかという「計算能力の競争」でした。
しかし2030年に向けて状況は変わりつつあります。
重要になるのは、
- どれだけ速く計算できるか ではなく、
- どれだけ速くデータを運べるか
です。
AI産業は今、計算中心の時代から通信中心の時代へ移行しつつあります。
通信が遅ければ、どれほど高性能なGPUを揃えても性能を発揮できません。
AIクラスタの巨大化が進むほど、通信能力そのものが競争力の源泉になります。
この変化が、光通信・光電融合・CPOなど次世代通信技術への投資を加速させているのです。
4.銅配線は限界を迎える
4-1.AI時代の課題は電力でもある
AIクラスタの巨大化によって浮上している課題は通信だけではありません。
もう一つの重要な課題が電力です。
近年発表されるAIデータセンターの建設計画を見ると、その電力規模は年々拡大しており、従来の数十メガワット級から、現在では数百メガワット級、将来的にはギガワット級の計画まで議論されています。
多くの人はAIデータセンターの電力消費というとGPUを思い浮かべます。
もちろんGPUは最大級の電力消費源ですが、実際には、
- ネットワークスイッチ
- 光トランシーバー
- 通信モジュール
- 冷却設備
なども膨大な電力を消費しています。
特にAIクラスタが巨大化すると、ネットワーク設備の重要性が急速に高まります。
なぜなら、数万台から数十万台のGPUを接続するためには、それに見合う巨大な通信インフラが必要になるからです。
AIモデルの規模が大きくなるほど、
- 計算量が増える
- 通信量が増える
- 通信設備が増える
- 消費電力が増える
という構造が生まれます。
つまりAI産業が成長を続けるためには、通信をより少ない電力で実現する技術が不可欠なのです。
4-2.銅配線の限界
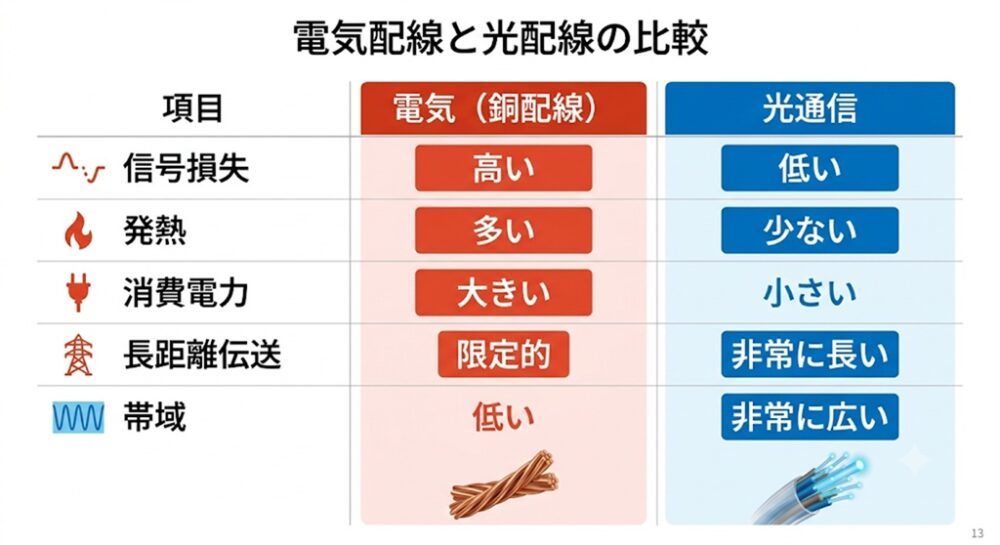
現在のコンピューターやサーバー内部では、主に電気信号が利用されており、その媒体として使われているのが銅配線です。
銅配線は長年にわたり情報産業を支えてきた成熟技術であり、製造コストも比較的低く、多くの機器で利用されています。
しかしAI時代になると、銅配線にはいくつかの根本的な課題が顕在化します。
① 信号損失(減衰)
電気信号は距離が長くなるほど弱くなります。高速通信では信号補正や増幅処理が必要となり、その分の電力消費が増加します。
② 発熱の増加
通信速度を向上させるほど回路から発生する熱も増加します。発熱は冷却コストを押し上げ、データセンター全体の電力効率を悪化させます。
③ 消費電力の増大
通信量が増えるほど、電気信号を維持するための電力も増加します。AIクラスタの通信量は指数的に増えるため、電力負荷も比例以上に増大します。
これらの課題は従来のデータセンターでは大きな問題ではありませんでした。
しかしAIクラスタが数十万GPU規模へ向かう時代では状況が一変します。
通信量そのものが桁違いに増加し、銅配線では対応しきれない領域に突入しつつあります。
これまで主役だった「計算能力」だけではなく、「通信効率」そのものが競争力になる時代が近づいているのです。
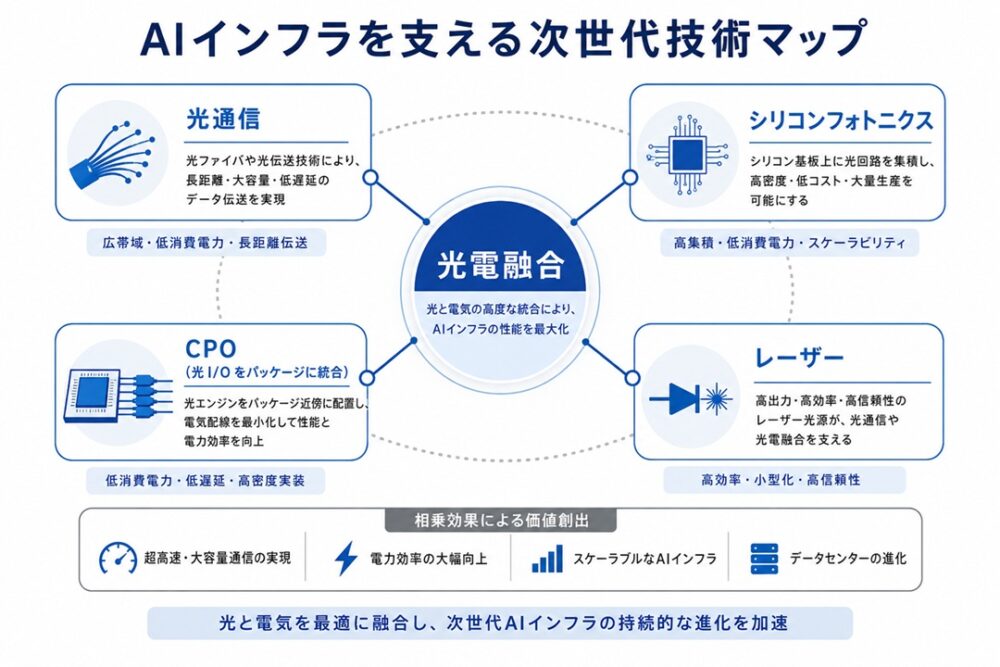
5.光電融合がAIインフラを変える
5-1.光通信が注目される理由
通信問題を解決する有力な手段として期待されているのが光通信です。
光通信自体は新しい技術ではなく、現在のインターネットは世界中に張り巡らされた光ファイバー網によって支えられています。海底ケーブルも都市間通信も、すでに光が主役です。
光通信には大きな利点があります。
- 圧倒的に大きな通信容量
光は電気信号よりもはるかに高い周波数帯域を利用できるため、膨大なデータを高速に伝送できます。 - 長距離伝送でも劣化が小さい
電気信号のように距離による減衰が大きくなく、補正回数も少なくて済みます。 - 消費電力が低い
電気信号のように増幅や補正を繰り返す必要がないため、電力効率が高い。
これまで光通信は主にデータセンター間や都市間通信で利用されてきました。
しかしAI時代になると状況は一変します。今後は、
- データセンター間
- データセンター内部
- サーバー内部
へと光通信が入り込んでいくと考えられています。
これは情報産業における大きな転換点であり、AIインフラの構造そのものを変える可能性があります。
5-2.光電融合とは何か
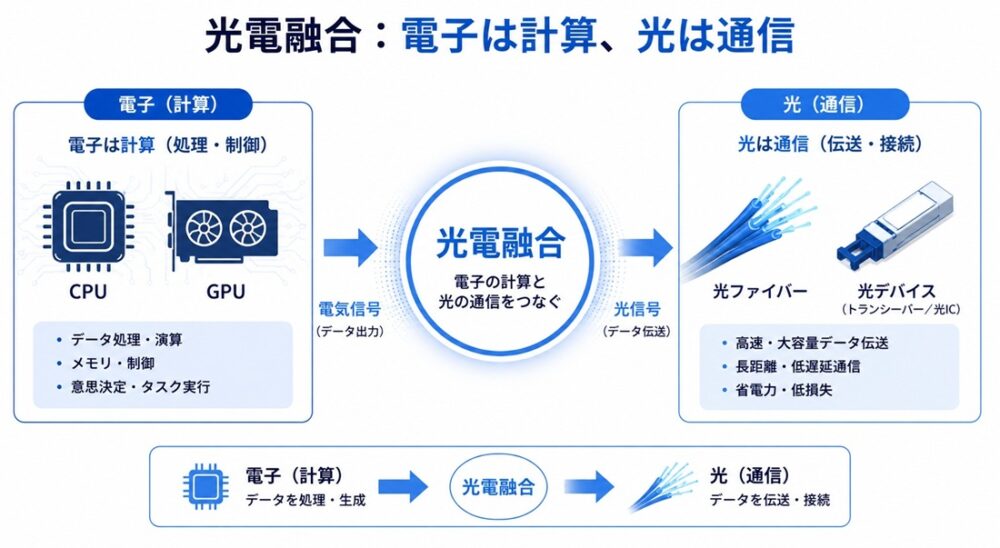
そこで注目されているのが光電融合です。
光電融合とは、電気信号と光信号を最適に組み合わせる技術です。
- 計算は電子(半導体)
- 通信は光(フォトニクス)
という役割分担を明確にすることで、
- 高速通信
- 低消費電力
- 発熱抑制
を同時に実現しようとするアプローチです。
現在、世界中の半導体メーカーや通信機器メーカーが光電融合技術の実用化を進めています。
これは単なる技術トレンドではなく、AI産業の成長を支えるための“基盤技術”として位置づけられています。
5-3.シリコンフォトニクスとは何か
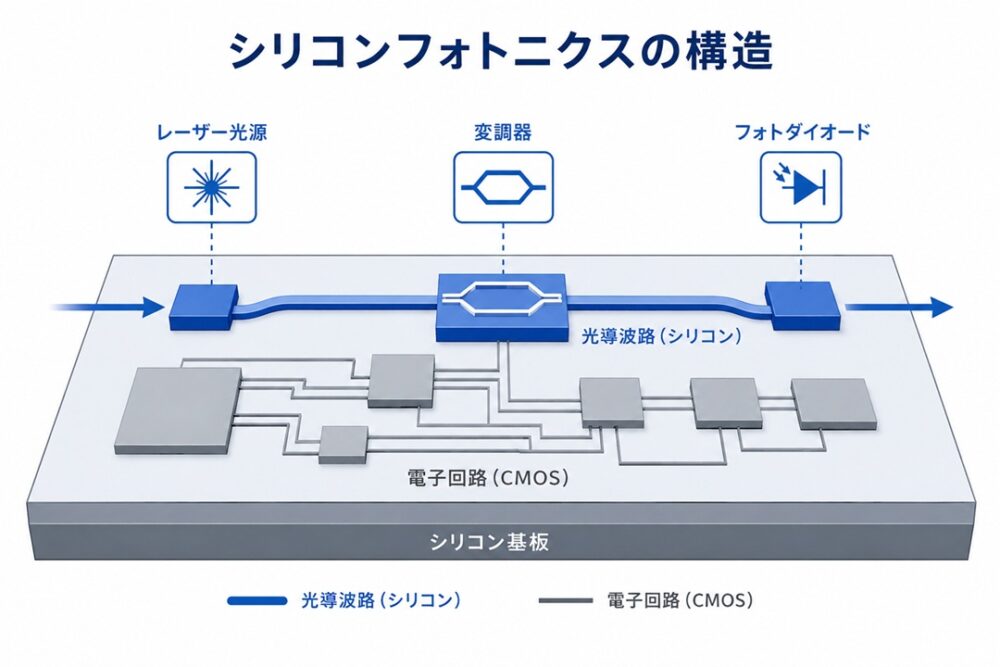
光電融合を支える中核技術として最も注目されているのがシリコンフォトニクスです。
シリコンフォトニクスとは、半導体製造技術を利用して光回路を形成する技術であり、電子回路と同じシリコン基板上に光デバイスを集積できる点が最大の特徴です。
従来の電子回路は電気信号を扱いますが、シリコンフォトニクスでは光信号を扱います。
これにより、
- 大規模量産が可能
- 小型化・低コスト化が進む
- 電子回路との近接配置が容易
といった利点が生まれます。
ただし、ここで重要な点があります。
シリコンフォトニクスだけでは光通信は成立しないということです。
光を発生させる“光源”が必要であり、その役割を担うのがレーザーです。
AI時代の光通信において、レーザーは極めて重要な存在であり、次回のテーマにもつながる核心部分です。
5-4.CPOが注目される理由
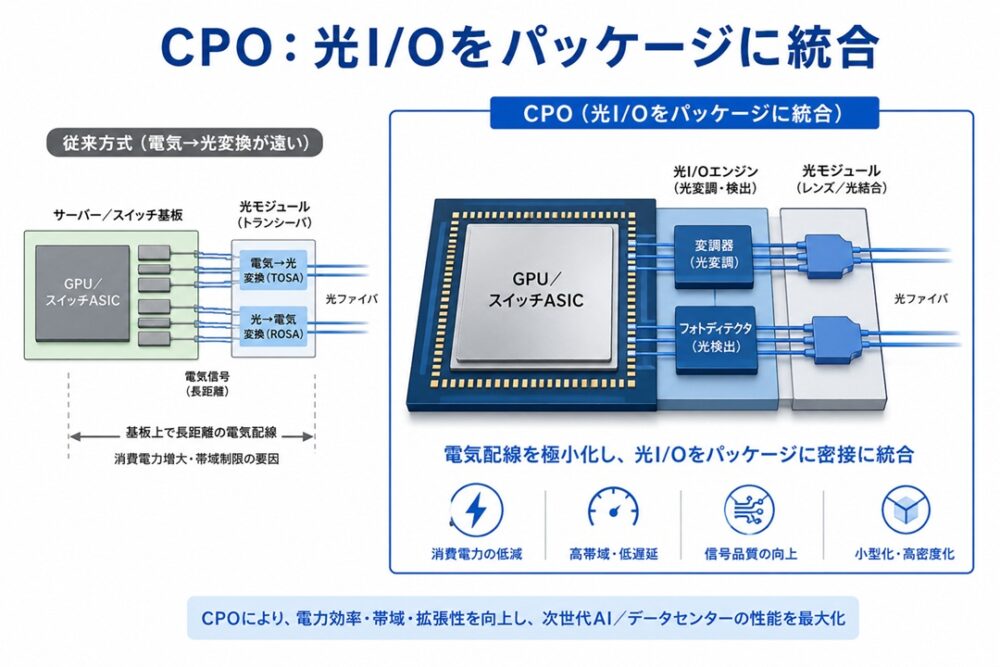
近年、AIインフラ分野で急速に注目されているのがCPO(Co-Packaged Optics)です。
CPOとは、光通信機能をGPUやネットワークスイッチの近く、あるいは同じパッケージ内に配置する技術です。
従来は、
- GPU → 電気信号で一定距離伝送
- 途中で光へ変換
- 光ファイバーで伝送
という構造でした。
しかし通信量が増加すると、この「電気伝送部分」が消費電力と発熱のボトルネックになります。
そこで生まれた発想が、「できるだけ早い段階で光へ変換する」というCPOの考え方です。
CPOによって、
- 通信速度の向上
- 消費電力の削減
- 発熱の抑制
が期待されます。AIクラスタが巨大化するほどCPOの効果は大きくなり、現在多くの企業が次世代技術として開発を進めています。
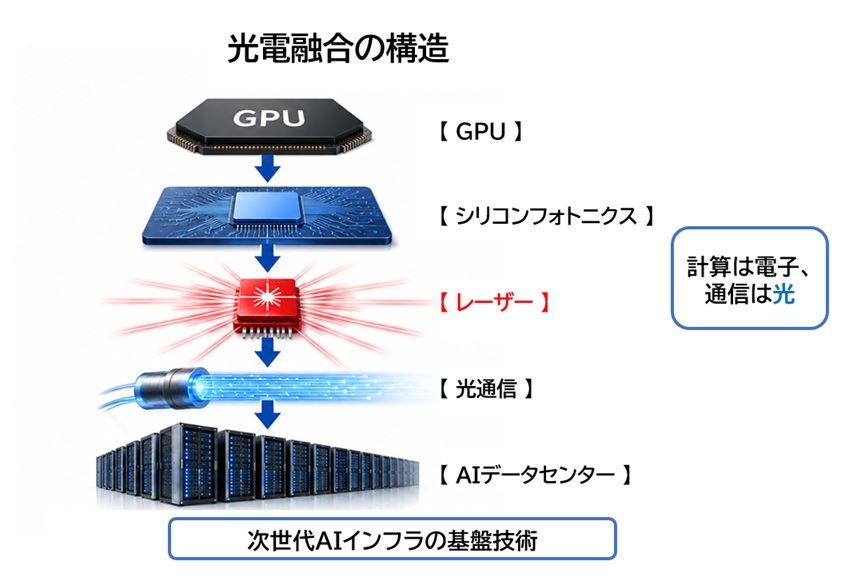
6.2030年、AI競争は通信で決まる
ここまで見てきたように、AI産業のボトルネックは常に移動してきました。
最初はGPUが不足し、次にHBMが不足し、さらにCoWoSが不足しました。
そして現在、その視線は確実に「通信」へ向かっています。
AIクラスタが数十万GPU規模へ拡大すると、通信能力そのものが競争力になります。
どれだけ高性能なGPUを揃えても、データを効率よく運べなければ性能を発揮できません。
これは高速道路に例えると分かりやすく、
- 高性能な自動車=GPU
- 道路網=通信インフラ
に相当します。
どれほど高性能な自動車を用意しても、道路が渋滞していれば速く移動できません。
AIインフラでも同じ現象が起き始めています。
今後のAI競争は、
- どれだけ速く計算できるか ではなく、
- どれだけ速くデータを運べるか
へと軸足を移す可能性があります。
これはAIインフラの価値基準が根本的に変わることを意味します。
2030年は、AI産業にとって「計算中心の時代」から「通信中心の時代」へ移行する転換点になるかもしれません。
光通信、光電融合、シリコンフォトニクス、CPOといった技術は、この新しい競争軸を支える基盤として急速に重要性を増しています。
AIの性能を決めるのは、もはやGPU単体のスペックではありません。
AIクラスタ全体として、どれだけ効率よく通信できるか。
これこそが2030年以降のAI競争の本質となるでしょう
まとめ
生成AIブームによって、AI産業はかつてないスピードで成長を続けています。
その過程で、AIインフラのボトルネックは常に移動してきました。
- GPU
- HBM
- CoWoS
- 通信
という順番で制約が次々と表面化し、AI産業はそのたびに新たな課題へ対応を迫られてきました。
現在のAI競争は一見するとGPU性能競争に見えます。
しかし2030年に向けて、本当の競争軸は通信へ移りつつあります。
AIクラスタが数十万GPU規模へ拡大すると、
- 通信量の爆発
- 消費電力の増加
- 発熱の増大
といった課題が顕著になり、従来の電気配線では対応しきれなくなります。
その解決策として期待されているのが、
- 光通信
- 光電融合
- シリコンフォトニクス
- CPO
といった次世代技術です。
そして、これらすべての出発点となるのが「レーザー」です。
光を発生できなければ光通信は成立しません。
つまり、AI時代の通信革命はレーザーから始まると言っても過言ではありません。
次回は、
- 2035年のAI競争を左右するのはレーザーだった
- 光電融合サプライチェーンの知られざる主役
をテーマに、AIインフラの未来を支えるレーザー技術と、そのサプライチェーンの全体像について詳しく解説します。
